RT-DETR改进策略【注意力机制篇】| WACV-2021 Triplet Attention 三重注意力模块 - 跨维度交互注意力机制优化
一、本文介绍
本文记录的是
利用
Triplet Attention
模块优化
RT-DETR
的目标检测网络模型
。
Triplet Attention
的作用在于通过
三个分支结构
捕捉跨维度交互,
同时包含通道信息和空间信息
,克服了常见注意力方法中
通道和空间分离计算
以及未考虑
跨维度交互
和
维度缩减
的问题。相比一些传统注意力机制,能更好地表达网络特征。本文将其应用到
RT-DETR
中,并进行
二次创新
,使网络能够综合多种维度信息,更好地突出重要特征,从而提升模型在不同任务中的性能。
二、Triplet Attention介绍
Rotate to Attend: Convolutional Triplet Attention Module
Triplet Attention Module
是一种轻量级的注意力机制模块,以下是对其模块设计的出发点、原理、结构和优势的详细介绍:
2.1 出发点
-
轻量级且高效的需求
:现有的注意力机制如
SE、CBAM等虽然有效,但存在一些问题。
例如CBAM在计算通道注意力时存在维度缩减,导致通道间非线性局部依赖关系的捕捉存在冗余,且部分方法需要较多额外的可学习参数。作者希望研究一种轻量级但有效的注意力机制,在保持或提高性能的同时,减少计算开销和参数数量。
-
强调跨维度交互的重要性
:在计算注意力权重时,捕捉跨维度交互对于提供丰富的特征表示非常重要。作者观察到现有的一些方法如
CBAM在通道注意力计算中未考虑跨维度交互,而这种交互对性能有积极影响。
2.2 原理
-
跨维度交互原理
:传统的通道注意力计算方法通常是为输入张量中的每个通道计算一个单一权重,然后使用该权重对特征图进行统一缩放。这种方法在计算通道注意力时,通常会通过全局平均池化将输入张量在空间上分解为每个通道一个像素,导致空间信息丢失,以及通道维度和空间维度之间的相互依赖关系缺失。
Triplet Attention通过在 三个分支中分别捕捉输入张量的不同维度组合( ( C , H ) (C, H) ( C , H ) 、 ( C , W ) (C, W) ( C , W ) 和 ( H , W ) (H, W) ( H , W ) )之间的依赖关系来解决这个问题。

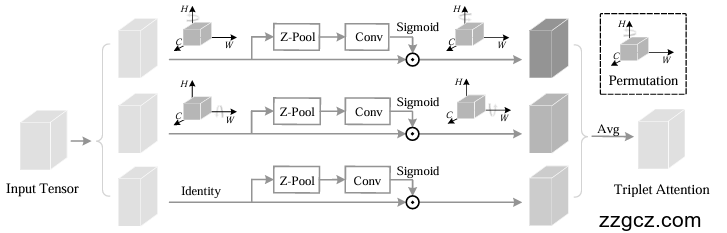
- 注意力权重计算 :对于每个分支,通过一系列操作计算注意力权重。首先对输入张量进行旋转操作,然后经过Z - pool层进行维度缩减,接着通过卷积层和批归一化层,最后通过sigmoid激活层生成注意力权重。这些权重用于对相应分支的特征进行加权,然后将三个分支的结果进行平均聚合,得到最终的输出张量。
2.3 结构
2.3.1 三个并行分支
- 两个跨维度交互分支 :其中 两个分支分别负责捕捉通道维度与空间维度( H H H 或 W W W )之间的跨维度交互 。
在第一个分支中,输入张量沿 H H H 轴逆时针旋转90°,然后经过Z - pool层、卷积层、批归一化层和sigmoid激活层生成注意力权重,再将权重应用于旋转后的张量并顺时针旋转90°恢复原始形状。第二个分支类似,只是沿 W W W 轴旋转。
-
一个空间注意力分支
:最后一个分支类似于
CBAM中的空间注意力模块,用于构建 空间注意力 。输入张量先经过Z - pool层,然后通过卷积层和批归一化层,最后通过sigmoid激活层生成 空间注意力权重 并应用于输入张量。
2.3.2 聚合操作
三个分支
的输出通过简单平均进行聚合,得到最终的精炼张量。
2.4 优势
-
计算开销小
:在计算注意力权重时,以可忽略的计算开销捕捉到丰富的判别性特征表示。例如在ResNet - 50上进行实验,与其他注意力机制相比,
Triplet Attention增加的参数和FLOP非常少,但能提高性能。 -
强调跨维度交互且无维度缩减
:与之前的方法不同,
Triplet Attention强调跨维度交互的重要性,并且在计算过程中没有维度缩减,避免了通道和权重之间的间接对应关系,从而能够更好地捕捉特征之间的关系,提供更有效的特征表示。 - 性能优势 :在多种计算机视觉任务上表现出色,如在ImageNet - 1k图像分类任务、MSCOCO和PASCAL VOC数据集的目标检测任务中,能够匹配或超越其他类似的注意力机制技术,同时引入的额外模型参数数量最少。
论文: https://arxiv.org/pdf/2010.03045.pdf
源码: https://github.com/landskape-ai/triplet-attention
三、Triplet Attention的实现代码
TripletAttention
及其改进的实现代码如下:
import torch
import torch.nn as nn
from ultralytics.nn.modules.conv import LightConv
class BasicConv(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, padding=0, dilation=1, groups=1, relu=True,
bn=True, bias=False):
super(BasicConv, self).__init__()
self.out_channels = out_planes
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, stride=stride, padding=padding,
dilation=dilation, groups=groups, bias=bias)
self.bn = nn.BatchNorm2d(out_planes, eps=1e-5, momentum=0.01, affine=True) if bn else None
self.relu = nn.ReLU() if relu else None
def forward(self, x):
x = self.conv(x)
if self.bn is not None:
x = self.bn(x)
if self.relu is not None:
x = self.relu(x)
return x
class ZPool(nn.Module):
def forward(self, x):
return torch.cat((torch.max(x, 1)[0].unsqueeze(1), torch.mean(x, 1).unsqueeze(1)), dim=1)
class AttentionGate(nn.Module):
def __init__(self):
super(AttentionGate, self).__init__()
kernel_size = 7
self.compress = ZPool()
self.conv = BasicConv(2, 1, kernel_size, stride=1, padding=(kernel_size - 1) // 2, relu=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.conv(x_compress)
scale = torch.sigmoid_(x_out)
return x * scale
class TripletAttention(nn.Module):
def __init__(self, no_spatial=False):
super(TripletAttention, self).__init__()
self.cw = AttentionGate()
self.hc = AttentionGate()
self.no_spatial = no_spatial
if not no_spatial:
self.hw = AttentionGate()
def forward(self, x):
x_perm1 = x.permute(0, 2, 1, 3).contiguous()
x_out1 = self.cw(x_perm1)
x_out11 = x_out1.permute(0, 2, 1, 3).contiguous()
x_perm2 = x.permute(0, 3, 2, 1).contiguous()
x_out2 = self.hc(x_perm2)
x_out21 = x_out2.permute(0, 3, 2, 1).contiguous()
if not self.no_spatial:
x_out = self.hw(x)
x_out = 1 / 3 * (x_out + x_out11 + x_out21)
else:
x_out = 1 / 2 * (x_out11 + x_out21)
return x_out
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class HGBlock_TripletAttention(nn.Module):
"""
HG_Block of PPHGNetV2 with 2 convolutions and LightConv.
https://github.com/PaddlePaddle/PaddleDetection/blob/develop/ppdet/modeling/backbones/hgnet_v2.py
"""
def __init__(self, c1, cm, c2, k=3, n=6, lightconv=False, shortcut=False, act=nn.ReLU()):
"""Initializes a CSP Bottleneck with 1 convolution using specified input and output channels."""
super().__init__()
block = LightConv if lightconv else Conv
self.m = nn.ModuleList(block(c1 if i == 0 else cm, cm, k=k, act=act) for i in range(n))
self.sc = Conv(c1 + n * cm, c2 // 2, 1, 1, act=act) # squeeze conv
self.ec = Conv(c2 // 2, c2, 1, 1, act=act) # excitation conv
self.add = shortcut and c1 == c2
self.cv = TripletAttention()
def forward(self, x):
"""Forward pass of a PPHGNetV2 backbone layer."""
y = [x]
y.extend(m(y[-1]) for m in self.m)
y = self.cv(self.ec(self.sc(torch.cat(y, 1))))
return y + x if self.add else y
四、创新模块
4.1 改进点1⭐
模块改进方法
:直接加入
TripletAttention模块
(
第五节讲解添加步骤
)。
TripletAttention模块
添加后如下:

4.2 改进点2⭐
模块改进方法
:基于
TripletAttention模块
的
HGBlock
(
第五节讲解添加步骤
)。
第二种改进方法是对
RT-DETR
中的
HGBlock模块
进行改进,并将
TripletAttention
在加入到
HGBlock
模块中。
改进代码如下:
对
HGBlock
模块进行改进,加入
TripletAttention模块
,并重命名为
HGBlock_TripletAttention
。
class PSA_TripletAttention(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert(c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = TripletAttention()
self.ffn = nn.Sequential(
Conv(self.c, self.c*2, 1),
Conv(self.c*2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))
注意❗:在
第五小节
中需要声明的模块名称为:
HGBlock_TripletAttention
。
五、添加步骤
5.1 修改一
① 在
ultralytics/nn/
目录下新建
AddModules
文件夹用于存放模块代码
② 在
AddModules
文件夹下新建
TripleAttention.py
,将
第三节
中的代码粘贴到此处

5.2 修改二
在
AddModules
文件夹下新建
__init__.py
(已有则不用新建),在文件内导入模块:
from .TripleAttention import *

5.3 修改三
在
ultralytics/nn/modules/tasks.py
文件中,需要在两处位置添加各模块类名称。
首先:导入模块

其次:在
parse_model函数
中注册
HGBlock_TripletAttention
模块


六、yaml模型文件
6.1 模型改进版本1
此处以
ultralytics/cfg/models/rt-detr/rtdetr-l.yaml
为例,在同目录下创建一个用于自己数据集训练的模型文件
rtdetr-l-TripletAttention.yaml
。
将
rtdetr-l.yaml
中的内容复制到
rtdetr-l-TripletAttention.yaml
文件下,修改
nc
数量等于自己数据中目标的数量。
📌 模型的修改方法是在
骨干网络
添加
TripletAttention模块
。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, HGStem, [32, 48]] # 0-P2/4
- [-1, 6, HGBlock, [48, 128, 3]] # stage 1
- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
- [-1, 6, HGBlock, [96, 512, 3]] # stage 2
- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 4-P4/16
- [-1, 6, HGBlock, [192, 1024, 5, True, False]] # cm, c2, k, light, shortcut
- [-1, 6, HGBlock, [192, 1024, 5, True, True]]
- [-1, 6, HGBlock, [192, 1024, 5, True, True]] # stage 3
- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 8-P5/32
- [-1, 1, TripletAttention, []] # stage 4
- [-1, 6, HGBlock, [384, 2048, 5, True, False]] # stage 4
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 10 input_proj.2
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 12, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [7, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 input_proj.1
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256]] # 16, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 17, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 19 input_proj.0
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (21), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 22, downsample_convs.0
- [[-1, 18], 1, Concat, [1]] # cat Y4
- [-1, 3, RepC3, [256]] # F4 (24), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 25, downsample_convs.1
- [[-1, 13], 1, Concat, [1]] # cat Y5
- [-1, 3, RepC3, [256]] # F5 (27), pan_blocks.1
- [[22, 25, 28], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
6.2 模型改进版本2⭐
此处以
ultralytics/cfg/models/rt-detr/rtdetr-l.yaml
为例,在同目录下创建一个用于自己数据集训练的模型文件
rtdetr-l-HGBlock_TripletAttention.yaml
。
将
rtdetr-l.yaml
中的内容复制到
rtdetr-l-HGBlock_TripletAttention.yaml
文件下,修改
nc
数量等于自己数据中目标的数量。
📌 模型的修改方法是将
骨干网络
中的
HGBlock模块
替换成
HGBlock_TripletAttention模块
。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, HGStem, [32, 48]] # 0-P2/4
- [-1, 6, HGBlock, [48, 128, 3]] # stage 1
- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
- [-1, 6, HGBlock, [96, 512, 3]] # stage 2
- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 4-P4/16
- [-1, 6, HGBlock_TripletAttention, [192, 1024, 5, True, False]] # cm, c2, k, light, shortcut
- [-1, 6, HGBlock_TripletAttention, [192, 1024, 5, True, True]]
- [-1, 6, HGBlock_TripletAttention, [192, 1024, 5, True, True]] # stage 3
- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 8-P5/32
- [-1, 6, HGBlock, [384, 2048, 5, True, False]] # stage 4
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 10 input_proj.2
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 12, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [7, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 input_proj.1
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256]] # 16, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 17, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 19 input_proj.0
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (21), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 22, downsample_convs.0
- [[-1, 17], 1, Concat, [1]] # cat Y4
- [-1, 3, RepC3, [256]] # F4 (24), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 25, downsample_convs.1
- [[-1, 12], 1, Concat, [1]] # cat Y5
- [-1, 3, RepC3, [256]] # F5 (27), pan_blocks.1
- [[21, 24, 27], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
七、成功运行结果
打印网络模型可以看到
TripletAttention
和
HGBlock_TripletAttention
已经加入到模型中,并可以进行训练了。
rtdetr-l-TripletAttention :
rtdetr-l-TripletAttention summary: 697 layers, 32,808,431 parameters, 32,808,431 gradients, 108.0 GFLOPs
from n params module arguments
0 -1 1 25248 ultralytics.nn.modules.block.HGStem [3, 32, 48]
1 -1 6 155072 ultralytics.nn.modules.block.HGBlock [48, 48, 128, 3, 6]
2 -1 1 1408 ultralytics.nn.modules.conv.DWConv [128, 128, 3, 2, 1, False]
3 -1 6 839296 ultralytics.nn.modules.block.HGBlock [128, 96, 512, 3, 6]
4 -1 1 5632 ultralytics.nn.modules.conv.DWConv [512, 512, 3, 2, 1, False]
5 -1 6 1695360 ultralytics.nn.modules.block.HGBlock [512, 192, 1024, 5, 6, True, False]
6 -1 6 2055808 ultralytics.nn.modules.block.HGBlock [1024, 192, 1024, 5, 6, True, True]
7 -1 6 2055808 ultralytics.nn.modules.block.HGBlock [1024, 192, 1024, 5, 6, True, True]
8 -1 1 11264 ultralytics.nn.modules.conv.DWConv [1024, 1024, 3, 2, 1, False]
9 -1 1 300 ultralytics.nn.AddModules.TripleAttention.TripletAttention[]
10 -1 6 6708480 ultralytics.nn.modules.block.HGBlock [1024, 384, 2048, 5, 6, True, False]
11 -1 1 524800 ultralytics.nn.modules.conv.Conv [2048, 256, 1, 1, None, 1, 1, False]
12 -1 1 789760 ultralytics.nn.modules.transformer.AIFI [256, 1024, 8]
13 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 7 1 262656 ultralytics.nn.modules.conv.Conv [1024, 256, 1, 1, None, 1, 1, False]
16 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
17 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
18 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
19 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
20 3 1 131584 ultralytics.nn.modules.conv.Conv [512, 256, 1, 1, None, 1, 1, False]
21 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
22 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
23 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
24 [-1, 18] 1 0 ultralytics.nn.modules.conv.Concat [1]
25 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
26 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
27 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
28 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
29 [22, 25, 28] 1 7303907 ultralytics.nn.modules.head.RTDETRDecoder [1, [256, 256, 256]]
rtdetr-l-TripletAttention summary: 697 layers, 32,808,431 parameters, 32,808,431 gradients, 108.0 GFLOPs
rtdetr-l-HGBlock_TripletAttention :
rtdetr-l-HGBlock_TripletAttention summary: 730 layers, 32,809,031 parameters, 32,809,031 gradients, 108.0 GFLOPs
from n params module arguments
0 -1 1 25248 ultralytics.nn.modules.block.HGStem [3, 32, 48]
1 -1 6 155072 ultralytics.nn.modules.block.HGBlock [48, 48, 128, 3, 6]
2 -1 1 1408 ultralytics.nn.modules.conv.DWConv [128, 128, 3, 2, 1, False]
3 -1 6 839296 ultralytics.nn.modules.block.HGBlock [128, 96, 512, 3, 6]
4 -1 1 5632 ultralytics.nn.modules.conv.DWConv [512, 512, 3, 2, 1, False]
5 -1 6 1695660 ultralytics.nn.AddModules.TripleAttention.HGBlock_TripletAttention[512, 192, 1024, 5, 6, True, False]
6 -1 6 2056108 ultralytics.nn.AddModules.TripleAttention.HGBlock_TripletAttention[1024, 192, 1024, 5, 6, True, True]
7 -1 6 2056108 ultralytics.nn.AddModules.TripleAttention.HGBlock_TripletAttention[1024, 192, 1024, 5, 6, True, True]
8 -1 1 11264 ultralytics.nn.modules.conv.DWConv [1024, 1024, 3, 2, 1, False]
9 -1 6 6708480 ultralytics.nn.modules.block.HGBlock [1024, 384, 2048, 5, 6, True, False]
10 -1 1 524800 ultralytics.nn.modules.conv.Conv [2048, 256, 1, 1, None, 1, 1, False]
11 -1 1 789760 ultralytics.nn.modules.transformer.AIFI [256, 1024, 8]
12 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 7 1 262656 ultralytics.nn.modules.conv.Conv [1024, 256, 1, 1, None, 1, 1, False]
15 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
17 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
18 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
19 3 1 131584 ultralytics.nn.modules.conv.Conv [512, 256, 1, 1, None, 1, 1, False]
20 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
22 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
23 [-1, 17] 1 0 ultralytics.nn.modules.conv.Concat [1]
24 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
25 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
26 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
27 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
28 [21, 24, 27] 1 7303907 ultralytics.nn.modules.head.RTDETRDecoder [1, [256, 256, 256]]
rtdetr-l-HGBlock_TripletAttention summary: 730 layers, 32,809,031 parameters, 32,809,031 gradients, 108.0 GFLOPs