RT-DETR改进策略【Conv和Transformer】| HiLo注意力机制 通过分离处理图像的高频和低频信息,高效处理图像特征
一、本文介绍
本文记录的是
利用
HiLo
改进
RT-DETR
检测模型
,针对目标检测中面临的
多尺度特征融合效率
与
长距离依赖建模
难题,HiLo注意力模块的引入旨在
通过频率解耦策略优化高分辨率特征处理
,
将高频细节(如目标边缘)与低频语义(如场景结构)分离建模
,提升目标检测精度。
二、HiLo介绍
Fast Vision Transformers with HiLo Attention
2.1 设计出发点
HiLo注意力模块的提出源于对传统自注意力机制局限性的反思。传统多头自注意力(MSA)在处理高分辨率图像时存在以下问题:
- 计算复杂度与实际速度脱节 :FLOPs作为间接指标无法准确反映模型在GPU/CPU上的真实运行速度,例如Focal-Tiny与Swin-Ti的FLOPs相近,但实际速度慢得多。
- 频率信息利用不足 :图像高频信息(局部细节)和低频信息(全局结构)在传统MSA中被统一处理,未能充分发挥各自特性。
2.2 结构设计
HiLo将注意力模块分为高频(Hi-Fi)和低频(Lo-Fi)两个分支,通过头部分割策略实现频率解耦:
-
高频分支(Hi-Fi)
:
- 采用局部窗口自注意力(如2×2窗口)捕捉局部细节。
- 避免复杂操作(如窗口偏移或多尺度划分),提升硬件友好性。
-
低频分支(Lo-Fi)
:
- 对每个窗口进行平均池化提取低频信号。
- 通过全局注意力建模低频特征间的长距离依赖,减少键值对长度以降低复杂度。
-
头部分割
:
- 将总头数按比例α分配给Hi-Fi和Lo-Fi(默认α=0.9),平衡局部与全局信息处理。

2.3 核心优势
- 高效性 :降低高分辨率下的内存访问成本,减少DRAM数据读取开销。
- 复杂度优化 :在14×14特征图上,HiLo的FLOPs比MSA减少约25%。
- 频率解耦效果 :FFT可视化显示Hi-Fi分支聚焦高频细节,Lo-Fi分支捕捉低频全局结构。
HiLo注意力模块通过频率解耦和硬件友好设计,为高效视觉Transformer提供了新范式,在速度与精度间取得了优异平衡。
论文: https://arxiv.org/pdf/2205.13213
源码: https://github.com/ziplab/LITv2
三、HiLo的实现代码
HiLo模块
的实现代码如下:
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.utils.torch_utils import fuse_conv_and_bn
# 论文:Fast Vision Transformers with HiLo Attention
# 论文地址:https://arxiv.org/abs/2205.13213
class HiLo(nn.Module):
"""
HiLo Attention
Link: https://arxiv.org/abs/2205.13213
"""
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., window_size=2, alpha=0.5):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
head_dim = int(dim/num_heads)
self.dim = dim
# self-attention heads in Lo-Fi
self.l_heads = int(num_heads * alpha)
# token dimension in Lo-Fi
self.l_dim = self.l_heads * head_dim
# self-attention heads in Hi-Fi
self.h_heads = num_heads - self.l_heads
# token dimension in Hi-Fi
self.h_dim = self.h_heads * head_dim
# local window size. The `s` in our paper.
self.ws = window_size
if self.ws == 1:
# ws == 1 is equal to a standard multi-head self-attention
self.h_heads = 0
self.h_dim = 0
self.l_heads = num_heads
self.l_dim = dim
self.scale = qk_scale or head_dim ** -0.5
# Low frequence attention (Lo-Fi)
if self.l_heads > 0:
if self.ws != 1:
self.sr = nn.AvgPool2d(kernel_size=window_size, stride=window_size)
self.l_q = nn.Linear(self.dim, self.l_dim, bias=qkv_bias)
self.l_kv = nn.Linear(self.dim, self.l_dim * 2, bias=qkv_bias)
self.l_proj = nn.Linear(self.l_dim, self.l_dim)
# High frequence attention (Hi-Fi)
if self.h_heads > 0:
self.h_qkv = nn.Linear(self.dim, self.h_dim * 3, bias=qkv_bias)
self.h_proj = nn.Linear(self.h_dim, self.h_dim)
def hifi(self, x):
B, H, W, C = x.shape
h_group, w_group = H // self.ws, W // self.ws
total_groups = h_group * w_group
x = x.reshape(B, h_group, self.ws, w_group, self.ws, C).transpose(2, 3)
qkv = self.h_qkv(x).reshape(B, total_groups, -1, 3, self.h_heads, self.h_dim // self.h_heads).permute(3, 0, 1, 4, 2, 5)
q, k, v = qkv[0], qkv[1], qkv[2] # B, hw, n_head, ws*ws, head_dim
attn = (q @ k.transpose(-2, -1)) * self.scale # B, hw, n_head, ws*ws, ws*ws
attn = attn.softmax(dim=-1)
attn = (attn @ v).transpose(2, 3).reshape(B, h_group, w_group, self.ws, self.ws, self.h_dim)
x = attn.transpose(2, 3).reshape(B, h_group * self.ws, w_group * self.ws, self.h_dim)
x = self.h_proj(x)
return x
def lofi(self, x):
B, H, W, C = x.shape
q = self.l_q(x).reshape(B, H * W, self.l_heads, self.l_dim // self.l_heads).permute(0, 2, 1, 3)
if self.ws > 1:
x_ = x.permute(0, 3, 1, 2)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
kv = self.l_kv(x_).reshape(B, -1, 2, self.l_heads, self.l_dim // self.l_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.l_kv(x).reshape(B, -1, 2, self.l_heads, self.l_dim // self.l_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
x = (attn @ v).transpose(1, 2).reshape(B, H, W, self.l_dim)
x = self.l_proj(x)
return x
def forward(self, x):
x = x.permute(0, 2, 3, 1)
if self.h_heads == 0:
x = self.lofi(x)
return x.permute(0, 3, 1, 2)
if self.l_heads == 0:
x = self.hifi(x)
return x.permute(0, 3, 1, 2)
hifi_out = self.hifi(x)
lofi_out = self.lofi(x)
x = torch.cat((hifi_out, lofi_out), dim=-1)
x = x.permute(0, 3, 1, 2)
return x
def flops(self, H, W):
# pad the feature map when the height and width cannot be divided by window size
Hp = self.ws * math.ceil(H / self.ws)
Wp = self.ws * math.ceil(W / self.ws)
Np = Hp * Wp
# For Hi-Fi
# qkv
hifi_flops = Np * self.dim * self.h_dim * 3
nW = (Hp // self.ws) * (Wp // self.ws)
window_len = self.ws * self.ws
# q @ k and attn @ v
window_flops = window_len * window_len * self.h_dim * 2
hifi_flops += nW * window_flops
# projection
hifi_flops += Np * self.h_dim * self.h_dim
# for Lo-Fi
# q
lofi_flops = Np * self.dim * self.l_dim
kv_len = (Hp // self.ws) * (Wp // self.ws)
# k, v
lofi_flops += kv_len * self.dim * self.l_dim * 2
# q @ k and attn @ v
lofi_flops += Np * self.l_dim * kv_len * 2
# projection
lofi_flops += Np * self.l_dim * self.l_dim
return hifi_flops + lofi_flops
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class Conv(nn.Module):
"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):
"""Initialize Conv layer with given arguments including activation."""
super().__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
"""Apply convolution, batch normalization and activation to input tensor."""
return self.act(self.bn(self.conv(x)))
def forward_fuse(self, x):
"""Perform transposed convolution of 2D data."""
return self.act(self.conv(x))
class LayerNorm(nn.Module):
""" LayerNorm that supports two data formats: channels_last (default) or channels_first.
The ordering of the dimensions in the inputs. channels_last corresponds to inputs with
shape (batch_size, height, width, channels) while channels_first corresponds to inputs
with shape (batch_size, channels, height, width).
"""
def __init__(self, normalized_shape, eps=1e-6, data_format="channels_first"):
super().__init__()
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.eps = eps
self.data_format = data_format
if self.data_format not in ["channels_last", "channels_first"]:
raise NotImplementedError
self.normalized_shape = (normalized_shape, )
def forward(self, x):
if self.data_format == "channels_last":
return F.layer_norm(x, self.normalized_shape, self.weight, self.bias, self.eps)
elif self.data_format == "channels_first":
u = x.mean(1, keepdim=True)
s = (x - u).pow(2).mean(1, keepdim=True)
x = (x - u) / torch.sqrt(s + self.eps)
x = self.weight[:, None, None] * x + self.bias[:, None, None]
return x
class AIFI_HiLo(nn.Module):
"""Defines a single layer of the transformer encoder."""
def __init__(self, c1, cm=2048, num_heads=8, dropout=0.0, act=nn.GELU(), normalize_before=False):
"""Initialize the TransformerEncoderLayer with specified parameters."""
super().__init__()
self.Attention = HiLo(c1)
self.fc1 = nn.Conv2d(c1, cm, 1)
self.fc2 = nn.Conv2d(cm, c1, 1)
self.norm1 = LayerNorm(c1)
self.norm2 = LayerNorm(c1)
self.dropout = nn.Dropout(dropout)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.act = act
self.normalize_before = normalize_before
def forward_post(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Performs forward pass with post-normalization."""
src2 = self.Attention(src)
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.fc2(self.dropout(self.act(self.fc1(src))))
src = src + self.dropout2(src2)
return self.norm2(src)
def forward(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Forward propagates the input through the encoder module."""
return self.forward_post(src, src_mask, src_key_padding_mask, pos)
四、创新模块
4.1 改进点⭐
模块改进方法
:直接加入
HiLo
(
第五节讲解添加步骤
)。
HiLo
模块加入如下:

4.2 改进点⭐
模块改进方法
:基于
HiLo模块
的
AIFI
(
第五节讲解添加步骤
)。
第二种改进方法是对
RT-DETR
中的
AIFI模块
进行改进,并将
HiLo
在加入到
AIFI
模块中。
改进代码如下:
对
AIFI
模块进行改进,加入
HiLo模块
。
class AIFI_HiLo(nn.Module):
"""Defines a single layer of the transformer encoder."""
def __init__(self, c1, cm=2048, num_heads=8, dropout=0.0, act=nn.GELU(), normalize_before=False):
"""Initialize the TransformerEncoderLayer with specified parameters."""
super().__init__()
self.Attention = HiLo(c1)
self.fc1 = nn.Conv2d(c1, cm, 1)
self.fc2 = nn.Conv2d(cm, c1, 1)
self.norm1 = LayerNorm(c1)
self.norm2 = LayerNorm(c1)
self.dropout = nn.Dropout(dropout)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.act = act
self.normalize_before = normalize_before
def forward_post(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Performs forward pass with post-normalization."""
src2 = self.Attention(src)
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.fc2(self.dropout(self.act(self.fc1(src))))
src = src + self.dropout2(src2)
return self.norm2(src)
def forward(self, src, src_mask=None, src_key_padding_mask=None, pos=None):
"""Forward propagates the input through the encoder module."""
return self.forward_post(src, src_mask, src_key_padding_mask, pos)

注意❗:在
第五小节
中需要声明的模块名称为:
HiLo
和
AIFI_HiLo
。
五、添加步骤
5.1 修改一
① 在
ultralytics/nn/
目录下新建
AddModules
文件夹用于存放模块代码
② 在
AddModules
文件夹下新建
HiLo.py
,将
第三节
中的代码粘贴到此处

5.2 修改二
在
AddModules
文件夹下新建
__init__.py
(已有则不用新建),在文件内导入模块:
from .HiLo import *

5.3 修改三
在
ultralytics/nn/modules/tasks.py
文件中,需要在两处位置添加各模块类名称。
首先:导入模块

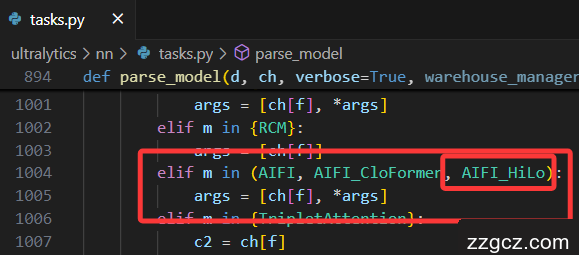
其次:在
parse_model函数
中注册
HiLo
和
AIFI_HiLo
模块

elif m in {HiLo}:
c2 = ch[f]
args = [c2, *args]

elif m in (AIFI_HiLo):
args = [ch[f], *args]
六、yaml模型文件
6.1 模型改进版本⭐
此处以
ultralytics/cfg/models/rt-detr/rtdetr-l.yaml
为例,在同目录下创建一个用于自己数据集训练的模型文件
rtdetr-l-AIFI_HiLo.yaml
。
将
rtdetr-l.yaml
中的内容复制到
rtdetr-l-AIFI_HiLo.yaml
文件下,修改
nc
数量等于自己数据中目标的数量。
📌 模型的修改方法是将
骨干网络
中添加
AIFI_HiLo模块
。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-l object detection model with P3-P5 outputs. For details see https://docs.ultralytics.com/models/rtdetr
# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, HGStem, [32, 48]] # 0-P2/4
- [-1, 6, HGBlock, [48, 128, 3]] # stage 1
- [-1, 1, DWConv, [128, 3, 2, 1, False]] # 2-P3/8
- [-1, 6, HGBlock, [128, 256, 3]] # stage 2
- [-1, 1, DWConv, [512, 3, 2, 1, False]] # 4-P4/16
- [-1, 6, HGBlock, [192, 1024, 5, True, False]] # cm, c2, k, light, shortcut
- [-1, 6, HGBlock, [192, 1024, 5, True, True]]
- [-1, 6, HGBlock, [192, 1024, 5, True, True]] # stage 3
- [-1, 1, DWConv, [1024, 3, 2, 1, False]] # 8-P5/32
- [-1, 6, HGBlock, [384, 2048, 5, True, False]] # stage 4
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 10 input_proj.2
- [-1, 1, AIFI_HiLo, [1024]]
- [-1, 1, Conv, [256, 1, 1]] # 12, Y5, lateral_convs.0
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [7, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 14 input_proj.1
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256]] # 16, fpn_blocks.0
- [-1, 1, Conv, [256, 1, 1]] # 17, Y4, lateral_convs.1
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 19 input_proj.0
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (21), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 22, downsample_convs.0
- [[-1, 17], 1, Concat, [1]] # cat Y4
- [-1, 3, RepC3, [256]] # F4 (24), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 25, downsample_convs.1
- [[-1, 12], 1, Concat, [1]] # cat Y5
- [-1, 3, RepC3, [256]] # F5 (27), pan_blocks.1
- [[21, 24, 27], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
6.2 模型改进版本⭐
此处以
ultralytics/cfg/models/rt-detr/rtdetr-resnet50.yaml
为例,在同目录下创建一个用于自己数据集训练的模型文件
rtdetr-HiLo.yaml
。
将
yolov10m.yaml
中的内容复制到
rtdetr-HiLo.yaml
文件下,修改
nc
数量等于自己数据中目标的数量。
📌 模型的修改方法是将
骨干网络
中添加
HiLo模块
。
# Ultralytics YOLO 🚀, AGPL-3.0 license
# RT-DETR-ResNet50 object detection model with P3-P5 outputs.
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n-cls.yaml' will call yolov8-cls.yaml with scale 'n'
# [depth, width, max_channels]
l: [1.00, 1.00, 1024]
backbone:
# [from, repeats, module, args]
- [-1, 1, ResNetLayer, [3, 64, 1, True, 1]] # 0
- [-1, 1, ResNetLayer, [64, 64, 1, False, 3]] # 1
- [-1, 1, ResNetLayer, [256, 128, 2, False, 4]] # 2
- [-1, 1, ResNetLayer, [512, 256, 2, False, 6]] # 3
- [-1, 1, ResNetLayer, [1024, 512, 2, False, 3]] # 4
- [-1, 1, HiLo, [1024]] # 5
head:
- [-1, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 6
- [-1, 1, AIFI, [1024, 8]]
- [-1, 1, Conv, [256, 1, 1]] # 8
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [3, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 10
- [[-2, -1], 1, Concat, [1]]
- [-1, 3, RepC3, [256]] # 12
- [-1, 1, Conv, [256, 1, 1]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [2, 1, Conv, [256, 1, 1, None, 1, 1, False]] # 15
- [[-2, -1], 1, Concat, [1]] # cat backbone P4
- [-1, 3, RepC3, [256]] # X3 (17), fpn_blocks.1
- [-1, 1, Conv, [256, 3, 2]] # 18, downsample_convs.0
- [[-1, 13], 1, Concat, [1]] # cat Y4
- [-1, 3, RepC3, [256]] # F4 (20), pan_blocks.0
- [-1, 1, Conv, [256, 3, 2]] # 21, downsample_convs.1
- [[-1, 8], 1, Concat, [1]] # cat Y5
- [-1, 3, RepC3, [256]] # F5 (23), pan_blocks.1
- [[17, 20, 23], 1, RTDETRDecoder, [nc]] # Detect(P3, P4, P5)
七、成功运行结果
打印网络模型可以看到
HiLo
和
AIFI_HiLo
已经加入到模型中,并可以进行训练了。
rtdetr-l-AIFI_HiLo :
rtdetr-l-AIFI_HiLo summary: 686 layers, 32,904,259 parameters, 32,904,259 gradients, 109.8 GFLOPs
from n params module arguments
0 -1 1 25248 ultralytics.nn.modules.block.HGStem [3, 32, 48]
1 -1 6 155072 ultralytics.nn.modules.block.HGBlock [48, 48, 128, 3, 6]
2 -1 1 1408 ultralytics.nn.modules.conv.DWConv [128, 128, 3, 2, 1, False]
3 -1 6 1034496 ultralytics.nn.modules.block.HGBlock [128, 128, 256, 3, 6]
4 -1 1 5632 ultralytics.nn.modules.conv.DWConv [256, 512, 3, 2, 1, False]
5 -1 6 1695360 ultralytics.nn.modules.block.HGBlock [512, 192, 1024, 5, 6, True, False]
6 -1 6 2055808 ultralytics.nn.modules.block.HGBlock [1024, 192, 1024, 5, 6, True, True]
7 -1 6 2055808 ultralytics.nn.modules.block.HGBlock [1024, 192, 1024, 5, 6, True, True]
8 -1 1 11264 ultralytics.nn.modules.conv.DWConv [1024, 1024, 3, 2, 1, False]
9 -1 6 6708480 ultralytics.nn.modules.block.HGBlock [1024, 384, 2048, 5, 6, True, False]
10 -1 1 524800 ultralytics.nn.modules.conv.Conv [2048, 256, 1, 1, None, 1, 1, False]
11 -1 1 756224 ultralytics.nn.AddModules.HiLo.AIFI_HiLo [256, 1024]
12 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
13 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
14 7 1 262656 ultralytics.nn.modules.conv.Conv [1024, 256, 1, 1, None, 1, 1, False]
15 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
16 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
17 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
18 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
19 3 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1, None, 1, 1, False]
20 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
21 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
22 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
23 [-1, 17] 1 0 ultralytics.nn.modules.conv.Concat [1]
24 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
25 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
26 [-1, 12] 1 0 ultralytics.nn.modules.conv.Concat [1]
27 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
28 [21, 24, 27] 1 7303907 ultralytics.nn.modules.head.RTDETRDecoder [1, [256, 256, 256]]
rtdetr-l-AIFI_HiLo summary: 686 layers, 32,904,259 parameters, 32,904,259 gradients, 109.8 GFLOPs
rtdetr-resnet50-HiLo :
rtdetr-resnet50-HiLo summary: 599 layers, 57,444,899 parameters, 57,444,899 gradients, 139.7 GFLOPs
from n params module arguments
0 -1 1 9536 ultralytics.nn.modules.block.ResNetLayer [3, 64, 1, True, 1]
1 -1 1 215808 ultralytics.nn.modules.block.ResNetLayer [64, 64, 1, False, 3]
2 -1 1 1219584 ultralytics.nn.modules.block.ResNetLayer [256, 128, 2, False, 4]
3 -1 1 7098368 ultralytics.nn.modules.block.ResNetLayer [512, 256, 2, False, 6]
4 -1 1 14964736 ultralytics.nn.modules.block.ResNetLayer [1024, 512, 2, False, 3]
5 -1 1 14682112 ultralytics.nn.AddModules.HiLo.HiLo [2048, 1024]
6 -1 1 524800 ultralytics.nn.modules.conv.Conv [2048, 256, 1, 1, None, 1, 1, False]
7 -1 1 789760 ultralytics.nn.modules.transformer.AIFI [256, 1024, 8]
8 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
9 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
10 3 1 262656 ultralytics.nn.modules.conv.Conv [1024, 256, 1, 1, None, 1, 1, False]
11 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
12 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
13 -1 1 66048 ultralytics.nn.modules.conv.Conv [256, 256, 1, 1]
14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest']
15 2 1 131584 ultralytics.nn.modules.conv.Conv [512, 256, 1, 1, None, 1, 1, False]
16 [-2, -1] 1 0 ultralytics.nn.modules.conv.Concat [1]
17 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
18 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
19 [-1, 13] 1 0 ultralytics.nn.modules.conv.Concat [1]
20 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
21 -1 1 590336 ultralytics.nn.modules.conv.Conv [256, 256, 3, 2]
22 [-1, 8] 1 0 ultralytics.nn.modules.conv.Concat [1]
23 -1 3 2232320 ultralytics.nn.modules.block.RepC3 [512, 256, 3]
24 [17, 20, 23] 1 7303907 ultralytics.nn.modules.head.RTDETRDecoder [1, [256, 256, 256]]
rtdetr-resnet50-HiLo summary: 599 layers, 57,444,899 parameters, 57,444,899 gradients, 139.7 GFLOPs