💡💡💡创新点:提出了一种基于内容引导注意力(CGA)的混合融合方案,将编码器部分的低级特征与相应的高级特征有效融合。
💡💡💡在多个数据集实现暴力涨点,适用于小目标,低对比度场景
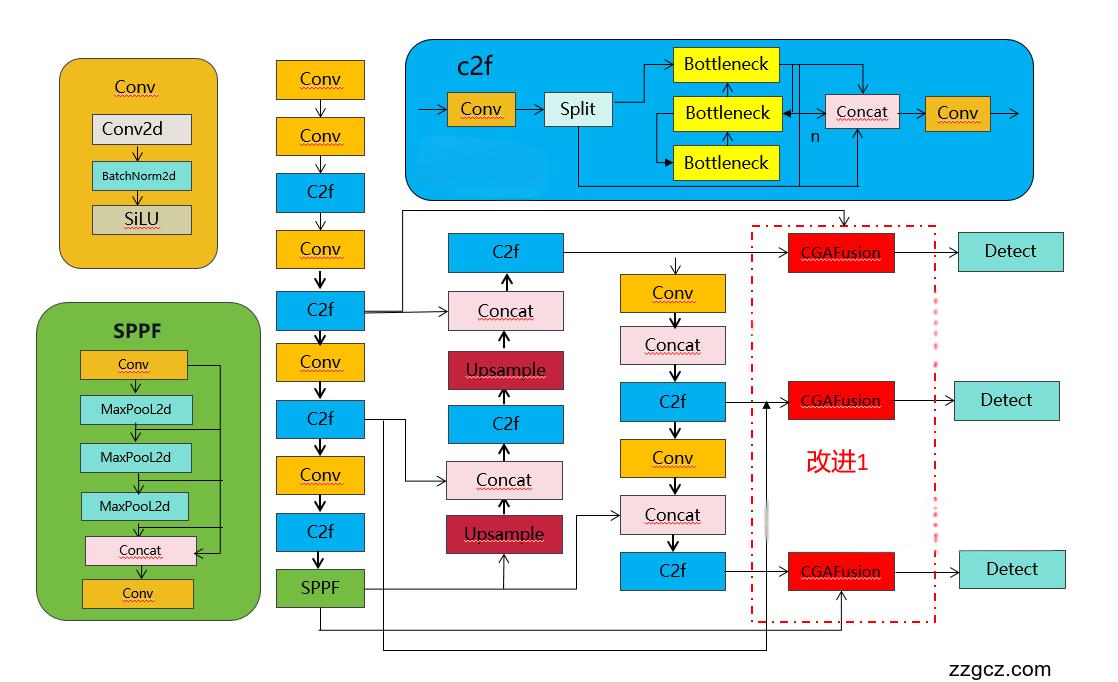
💡💡💡如何跟YOLOv8结合:将backbone和neck的特征融合,改进结构图如下
收录
YOLOv8原创自研
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.原理介绍

论文: https://arxiv.org/abs/2301.04805
摘要: 单幅图像去雾是一个具有挑战性的不适定问题,它需要从观测到的模糊图像中估计出潜在的无雾图像。现有的一些基于深度学习的方法致力于通过增加卷积的深度或宽度来提高模型的性能。卷积神经网络(CNN)结构的学习能力尚未得到充分的研究。本文提出了一种由细节增强卷积(DEConv)和内容引导注意(CGA)组成的细节增强注意块(DEAB)来增强特征学习,从而提高去雾性能。具体来说,DEConv将先验信息整合到正卷积层中,增强了表示和泛化能力。然后,通过使用重新参数化技术,将DEConv等效地转换为没有额外参数和计算成本的普通卷积。通过为每个信道分配唯一的空间重要性映射(SIM), CGA可以获得更多编码在特征中的有用信息。此外,提出了一种基于cgaba的混合融合方案,可以有效地融合特征并辅助梯度流。通过结合上述组件,我们提出了用于恢复高质量无雾图像的细节增强注意力网络(DEA-Net)。大量的实验结果证明了我们的DEA-Net的有效性,通过仅使用3.653 M参数将PSNR指数提高到41 dB以上,优于最先进的(SOTA)方法。

图2所示。我们提出的细节增强注意力网络(DEA-Net)的整体架构是一个三层编码器-解码器结构。DEA-Net包含三个部分:编码器部分、特征变换部分和解码器部分。我们在特征转换部分部署细节增强注意块(deab),在其余部分部署细节增强块(deb)。

图2 (d)显示了提出的基于cga的混合融合方案的细节。核心部分是我们选择使用CGA来计算特征调制的空间权重。将编码器部分的低级特征和相应的高级特征输入到CGA中计算权重,然后采用加权求和的方法进行组合。我们还通过跳跃连接增加输入特征,以缓解梯度消失问题,简化学习过程。最后,对融合后的特征进行1 × 1卷积层的投影,得到最终的特征(即Ffuse)。
图6所示。内容引导注意(CGA)图。CGA是一个从粗到精的过程:首先生成SIMs的粗版本(即Wcoa∈RC×H×W),然后在输入特征的引导下对每个通道进行细化。
我们提出了一种新的注意力机制,即内容引导注意力(CGA),以一种从粗到精的方式生成特定频道的SIMs。CGA通过输入特征引导SIM的生成,为每个通道分配唯一的SIM,使模型参加每个通道的重要区域。因此,可以强调特征中编码的更多有用信息,从而有效地提高性能。此外,提出了一种基于cgaba的混合融合方案,将编码器部分的低级特征与相应的高级特征有效融合。

2. CGAFusion加入YOLOv8
2.1 新建ultralytics/nn/DEANet.py
import torch
from torch import nn
from einops import rearrange
class SpatialAttention_CGA(nn.Module):
def __init__(self):
super(SpatialAttention_CGA, self).__init__()
self.sa = nn.Conv2d(2, 1, 7, padding=3, padding_mode='reflect' ,bias=True)
def forward(self, x):
x_avg = torch.mean(x, dim=1, keepdim=True)
x_max, _ = torch.max(x, dim=1, keepdim=True)
x2 = torch.concat([x_avg, x_max], dim=1)
sattn = self.sa(x2)
return sattn
class ChannelAttention_CGA(nn.Module):
def __init__(self, dim, reduction = 8):
super(ChannelAttention_CGA, self).__init__()
self.gap = nn.AdaptiveAvgPool2d(1)
self.ca = nn.Sequential(
nn.Conv2d(dim, dim // reduction, 1, padding=0, bias=True),
nn.ReLU(inplace=True),
nn.Conv2d(dim // reduction, dim, 1, padding=0, bias=True),
)
def forward(self, x):
x_gap = self.gap(x)
cattn = self.ca(x_gap)
return cattn
class PixelAttention_CGA(nn.Module):
def __init__(self, dim):
super(PixelAttention_CGA, self).__init__()
self.pa2 = nn.Conv2d(2 * dim, dim, 7, padding=3, padding_mode='reflect' ,groups=dim, bias=True)
self.sigmoid = nn.Sigmoid()
def forward(self, x, pattn1):
B, C, H, W = x.shape
x = x.unsqueeze(dim=2) # B, C, 1, H, W
pattn1 = pattn1.unsqueeze(dim=2) # B, C, 1, H, W
x2 = torch.cat([x, pattn1], dim=2) # B, C, 2, H, W
x2 = rearrange(x2, 'b c t h w -> b (c t) h w')
pattn2 = self.pa2(x2)
pattn2 = self.sigmoid(pattn2)
return pattn2
class CGAFusion(nn.Module):
def __init__(self, dim, reduction=8):
super(CGAFusion, self).__init__()
self.sa = SpatialAttention_CGA()
self.ca = ChannelAttention_CGA(dim, reduction)
self.pa = PixelAttention_CGA(dim)
self.conv = nn.Conv2d(dim, dim, 1, bias=True)
self.sigmoid = nn.Sigmoid()
def forward(self, data):
x, y = data
initial = x + y
cattn = self.ca(initial)
sattn = self.sa(initial)
pattn1 = sattn + cattn
pattn2 = self.sigmoid(self.pa(initial, pattn1))
result = initial + pattn2 * x + (1 - pattn2) * y
result = self.conv(result)
return result2.2 修改task.py
1)首先进行注册
from ultralytics.nn.DEANet import CGAFusion2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
elif m is CGAFusion:
c2 = ch[f[1]]
args = [c2, *args]
2.3 yolov8-CGAFusion.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[4, 15], 1, CGAFusion, []] # 22 (P3/8-small)
- [[6, 18], 1, CGAFusion, []] # 23 (P4/16-medium)
- [[9, 21], 1, CGAFusion, []] # 24 (P5/32-large)
- [[22, 23, 24], 1, Detect, [nc]] # Detect(P3, P4, P5)