💡💡💡本文独家改进:卷积和注意力融合模块(CAFMAttention),增强对全局和局部特征的提取能力,2024年最新的改进思路
💡💡💡创新点:卷积和注意力巧妙设计
💡💡💡如何跟YOLOv8结合:1)放在backbone后增强对全局和局部特征的提取能力;2)放在detect前面,增强detect提取能力;提供多种改进方法
💡💡💡多个私有数据集涨点明显,如缺陷检测NEU-DET、农业病害检测等;
改进1结构图如下:
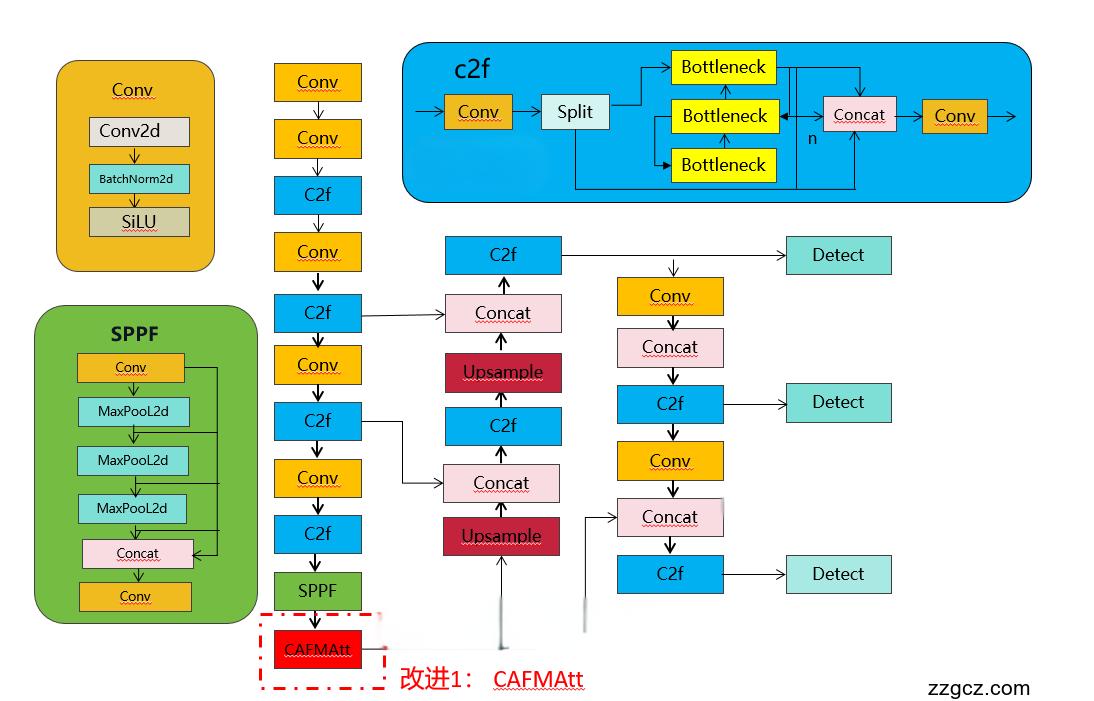
改进2结构图如下:
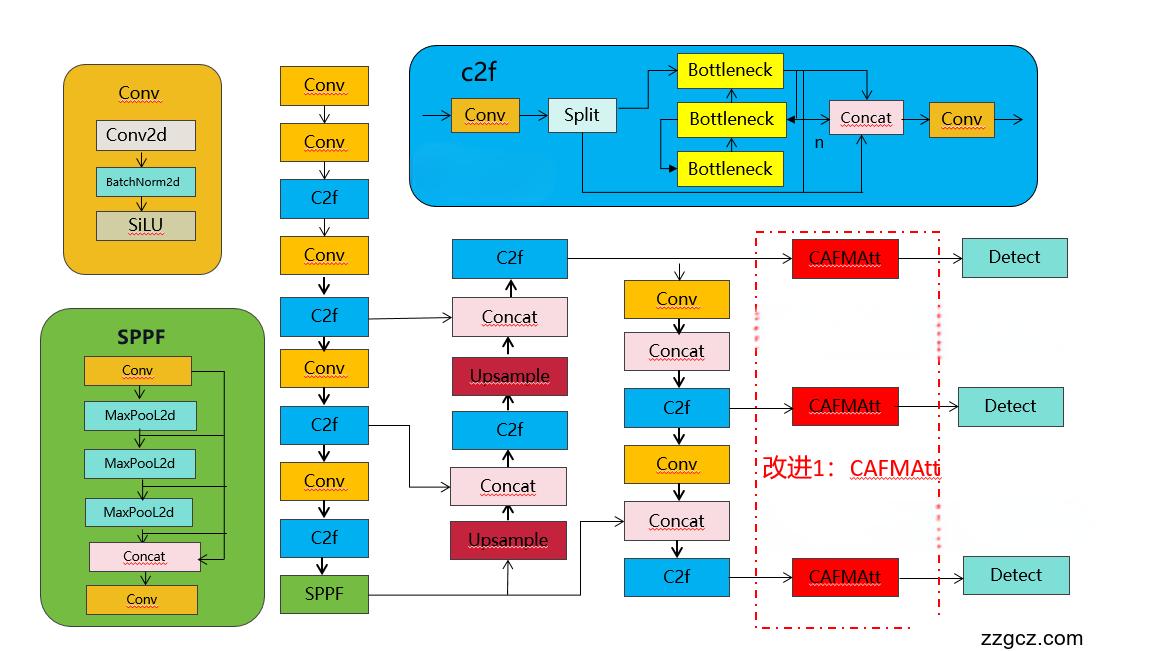
收录
YOLOv8原创自研
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.原理介绍

论文: https://arxiv.org/pdf/2403.10067.pdf
摘要:高光谱图像去噪对于高光谱数据的有效分析和解释至关重要。然而,同时建模全局和局部特征以增强HSI去噪的研究很少。在这封信中,我们提出了一个混合卷积和注意力网络(HCANet),它利用了卷积神经网络(cnn)和变压器的优势。为了增强对全局和局部特征的建模,我们设计了一个卷积和注意力融合模块,旨在捕获远程依赖关系和邻域光谱相关性。此外,为了改善多尺度信息聚合,我们设计了一个多尺度前馈网络,通过提取不同尺度的特征来增强去噪性能。在主流HSI数据集上的实验结果验证了该算法的合理性和有效性。该模型能够有效地去除各种类型的复杂噪声。
为了解决上述两个挑战,我们提出了一种用于HSI去噪的混合卷积和注意网络(HCANet),它同时利用了全局上下文信息和局部特征,如图1所示。具体来说,为了增强全局和局部特征的建模,我们设计了一个卷积和注意力融合模块(CAFM),旨在捕获远程依赖关系和邻域光谱相关性。此外,为了改善FFN的多尺度信息聚合,我们设计了一个多尺度前馈网络(MSFN),通过提取不同尺度的特征来增强去噪性能。在MSFN中使用了三个不同步长的平行扩展卷积。通过在两个真实数据集上进行实验,我们验证了我们提出的HCANet优于其他最先进的竞争对手。

图1所示。我们提出的用于HSI去噪的混合卷积和注意网络(HCANet)的说明。(a) HCANet框架。(b)CAMixing内部结构图。

图2所示。所提出的卷积和注意融合模块(CAFM)的示意图。它由全局和局部分支机构组成。在局部分支中,采用卷积和信道变换进行局部特征提取。在全局分支中,注意机制被用于建模远程特征依赖。
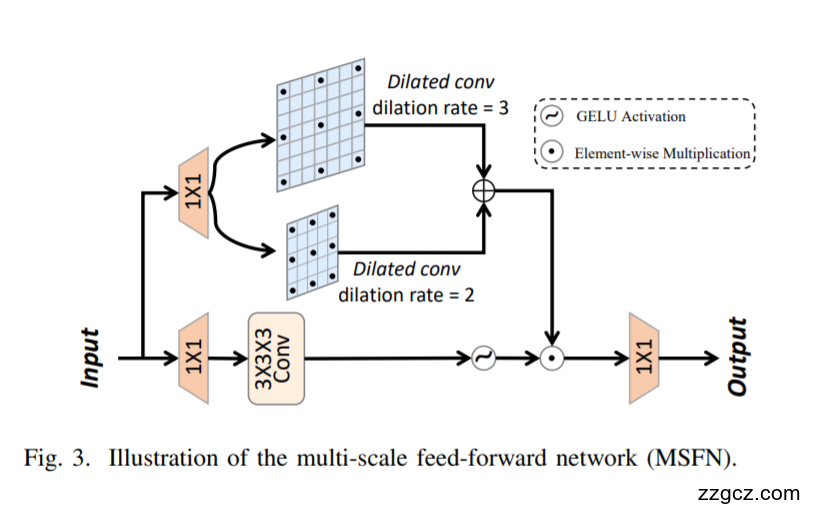
我们提出了用于高光谱图像去噪的混合卷积和注意网络(HCANet)。如图1所示,模型的主要结构是一个Ushaped网络,其中包含多个Convolution Attention Mixing (CAMixing)块。每个混合块包括两个部分:卷积-注意融合模块(CAFM)和多尺度前馈网络(MSFN)。对于HSI, 3D卷积全面捕获空间和光谱特征,但增加了参数。为了管理复杂性,我们使用2D卷积进行通道调整,有效地利用了HSI特征
2.CAFMAttention将入到YOLOv8
2.1 加入ultralytics/nn/backbone/HCANet.py
import sys
import torch
import torch.nn as nn
import torch.nn.functional as F
from pdb import set_trace as stx
import numbers
from einops import rearrange
import os
sys.path.append(os.getcwd())
# m_seed = 1
# # 设置seed
# torch.manual_seed(m_seed)
# torch.cuda.manual_seed_all(m_seed)
def to_3d(x):
return rearrange(x, 'b c h w -> b (h w) c')
def to_4d(x,h,w):
return rearrange(x, 'b (h w) c -> b c h w',h=h,w=w)
class BiasFree_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(BiasFree_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
sigma = x.var(-1, keepdim=True, unbiased=False)
return x / torch.sqrt(sigma+1e-5) * self.weight
class WithBias_LayerNorm(nn.Module):
def __init__(self, normalized_shape):
super(WithBias_LayerNorm, self).__init__()
if isinstance(normalized_shape, numbers.Integral):
normalized_shape = (normalized_shape,)
normalized_shape = torch.Size(normalized_shape)
assert len(normalized_shape) == 1
self.weight = nn.Parameter(torch.ones(normalized_shape))
self.bias = nn.Parameter(torch.zeros(normalized_shape))
self.normalized_shape = normalized_shape
def forward(self, x):
mu = x.mean(-1, keepdim=True)
sigma = x.var(-1, keepdim=True, unbiased=False)
return (x - mu) / torch.sqrt(sigma+1e-5) * self.weight + self.bias
class LayerNorm(nn.Module):
def __init__(self, dim, LayerNorm_type):
super(LayerNorm, self).__init__()
if LayerNorm_type =='BiasFree':
self.body = BiasFree_LayerNorm(dim)
else:
self.body = WithBias_LayerNorm(dim)
def forward(self, x):
h, w = x.shape[-2:]
return to_4d(self.body(to_3d(x)), h, w)
##########################################################################
## Multi-Scale Feed-Forward Network (MSFN)
class MSFN(nn.Module):
def __init__(self, dim, ffn_expansion_factor=2.66, bias=False):
super(MSFN, self).__init__()
hidden_features = int(dim*ffn_expansion_factor)
self.project_in = nn.Conv3d(dim, hidden_features*3, kernel_size=(1,1,1), bias=bias)
self.dwconv1 = nn.Conv3d(hidden_features, hidden_features, kernel_size=(3,3,3), stride=1, dilation=1, padding=1, groups=hidden_features, bias=bias)
# self.dwconv2 = nn.Conv3d(hidden_features, hidden_features, kernel_size=(3,3,3), stride=1, dilation=2, padding=2, groups=hidden_features, bias=bias)
# self.dwconv3 = nn.Conv3d(hidden_features, hidden_features, kernel_size=(3,3,3), stride=1, dilation=3, padding=3, groups=hidden_features, bias=bias)
self.dwconv2 = nn.Conv2d(hidden_features, hidden_features, kernel_size=(3,3), stride=1, dilation=2, padding=2, groups=hidden_features, bias=bias)
self.dwconv3 = nn.Conv2d(hidden_features, hidden_features, kernel_size=(3,3), stride=1, dilation=3, padding=3, groups=hidden_features, bias=bias)
self.project_out = nn.Conv3d(hidden_features, dim, kernel_size=(1,1,1), bias=bias)
def forward(self, x):
x = x.unsqueeze(2)
x = self.project_in(x)
x1,x2,x3 = x.chunk(3, dim=1)
x1 = self.dwconv1(x1).squeeze(2)
x2 = self.dwconv2(x2.squeeze(2))
x3 = self.dwconv3(x3.squeeze(2))
# x1 = self.dwconv1(x1)
# x2 = self.dwconv2(x2)
# x3 = self.dwconv3(x3)
x = F.gelu(x1)*x2*x3
x = x.unsqueeze(2)
x = self.project_out(x)
x = x.squeeze(2)
return x
##########################################################################
## Convolution and Attention Fusion Module (CAFM)
class CAFMAttention(nn.Module):
def __init__(self, dim, num_heads=2, bias=False):
super(CAFMAttention, self).__init__()
self.num_heads = num_heads
self.temperature = nn.Parameter(torch.ones(num_heads, 1, 1))
self.qkv = nn.Conv3d(dim, dim*3, kernel_size=(1,1,1), bias=bias)
self.qkv_dwconv = nn.Conv3d(dim*3, dim*3, kernel_size=(3,3,3), stride=1, padding=1, groups=dim*3, bias=bias)
self.project_out = nn.Conv3d(dim, dim, kernel_size=(1,1,1), bias=bias)
self.fc = nn.Conv3d(3*self.num_heads, 9, kernel_size=(1,1,1), bias=True)
self.dep_conv = nn.Conv3d(9*dim//self.num_heads, dim, kernel_size=(3,3,3), bias=True, groups=dim//self.num_heads, padding=1)
def forward(self, x):
b,c,h,w = x.shape
x = x.unsqueeze(2)
qkv = self.qkv_dwconv(self.qkv(x))
qkv = qkv.squeeze(2)
f_conv = qkv.permute(0,2,3,1)
f_all = qkv.reshape(f_conv.shape[0], h*w, 3*self.num_heads, -1).permute(0, 2, 1, 3)
f_all = self.fc(f_all.unsqueeze(2))
f_all = f_all.squeeze(2)
#local conv
f_conv = f_all.permute(0, 3, 1, 2).reshape(x.shape[0], 9*x.shape[1]//self.num_heads, h, w)
f_conv = f_conv.unsqueeze(2)
out_conv = self.dep_conv(f_conv) # B, C, H, W
out_conv = out_conv.squeeze(2)
# global SA
q,k,v = qkv.chunk(3, dim=1)
q = rearrange(q, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
k = rearrange(k, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
v = rearrange(v, 'b (head c) h w -> b head c (h w)', head=self.num_heads)
q = torch.nn.functional.normalize(q, dim=-1)
k = torch.nn.functional.normalize(k, dim=-1)
attn = (q @ k.transpose(-2, -1)) * self.temperature
attn = attn.softmax(dim=-1)
out = (attn @ v)
out = rearrange(out, 'b head c (h w) -> b (head c) h w', head=self.num_heads, h=h, w=w)
out = out.unsqueeze(2)
out = self.project_out(out)
out = out.squeeze(2)
output = out + out_conv
return output
2.2修改task.py
本文改进基于官方最新版本,如新加入C2fAttn等等
下载地址:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
1)首先进行注册
from ultralytics.nn.backbone.HCANet import CAFMAttention2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
只需要在你源码基础上加入CAFMAttention,其他模块为博主其他文章的优化点
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
CAFMAttention
):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3):
args.insert(2, n) # number of repeats
n = 1
2.3 yolov8-CAFMAttention.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, CAFMAttention, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.4 yolov8-CAFMAttention1.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [15, 1, CAFMAttention, [256]] # 22
- [18, 1, CAFMAttention, [512]] # 23
- [21, 1, CAFMAttention, [1024]] # 24
- [[22, 23, 24], 1, Detect, [nc]] # Detect(P3, P4, P5)