💡💡💡创新点:star operation(元素乘法)在无需加宽网络下,将输入映射到高维非线性特征空间的能力,逐元素乘法(star operation)在性能上始终优于求和,基于star operation块做二次创新
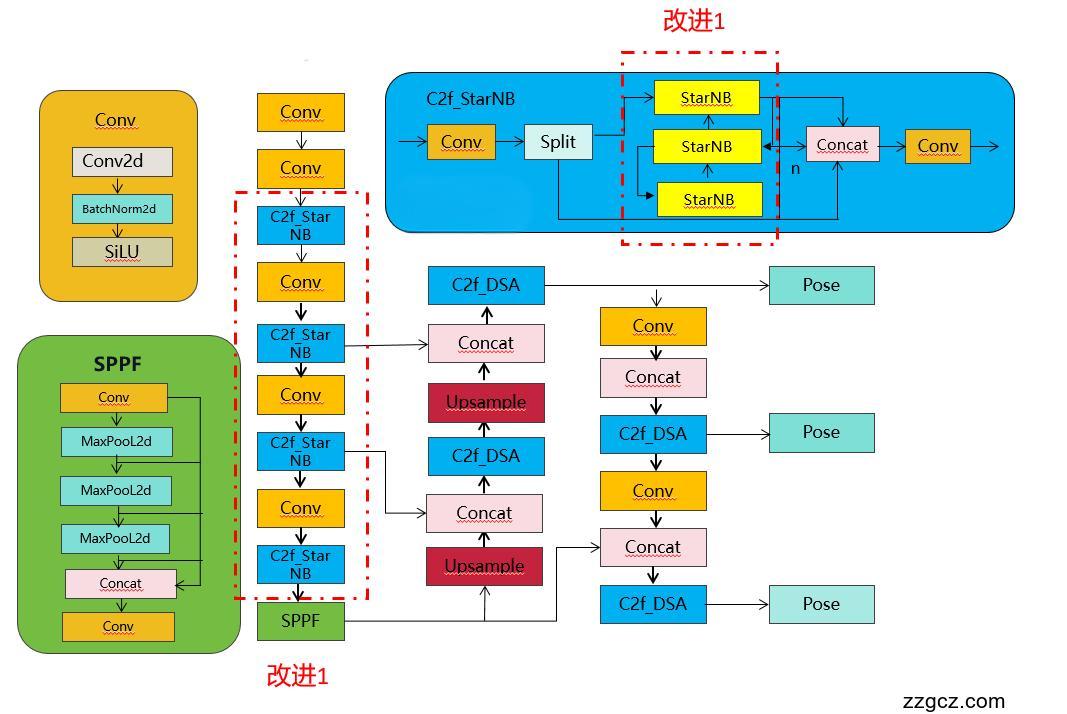
💡💡💡如何跟YOLOv8结合:替代YOLOv8的C2f,结构图如下
YOLOv8原创自研
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.原理介绍

论文:https://arxiv.org/pdf/2403.19967
摘要:最近的研究引起了人们对网络设计中尚未开发的“星型操作”(元素智能乘法)潜力的关注。虽然有很多直观的解释,但其应用背后的基本原理在很大程度上仍未被探索。我们的研究试图揭示明星手术将输入映射到高维、非线性特征空间的能力——类似于核技巧——无需扩大网络。我们进一步介绍了StarNet,一个简单而强大的原型,在紧凑的网络结构和高效的预算下展示了令人印象深刻的性能和低延迟。就像天上的星星一样,星星的运作看起来不起眼,但却蕴藏着巨大的潜力。
为了便于说明,构建了一个用于图像分类的demo block,如图 1 左侧所示。通过在stem层后堆叠多个demo block,论文构建了一个名为DemoNet的简单模型。保持所有其他因素不变,论文观察到逐元素乘法(star operation)在性能上始终优于求和,如图 1 右侧所示。

最近,通过元素乘法融合不同的子空间特征的学习范式越来越受到关注,论文将这种范例称为star operation(由于元素乘法符号类似于星形)。

2. starnet加入YOLOv8
2.1 新建ultralytics/nn/backbone/starnet.py
import torch
import torch.nn as nn
from timm.models.layers import DropPath, trunc_normal_
from timm.models.registry import register_model
from ultralytics.nn.modules import (Conv,C3, Bottleneck,C2f)
model_urls = {
"starnet_s1": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s1.pth.tar",
"starnet_s2": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s2.pth.tar",
"starnet_s3": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s3.pth.tar",
"starnet_s4": "https://github.com/ma-xu/Rewrite-the-Stars/releases/download/checkpoints_v1/starnet_s4.pth.tar",
}
class ConvBN(torch.nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size=1, stride=1, padding=0, dilation=1, groups=1, with_bn=True):
super().__init__()
self.add_module('conv', torch.nn.Conv2d(in_planes, out_planes, kernel_size, stride, padding, dilation, groups))
if with_bn:
self.add_module('bn', torch.nn.BatchNorm2d(out_planes))
torch.nn.init.constant_(self.bn.weight, 1)
torch.nn.init.constant_(self.bn.bias, 0)
class StarNetBlock(nn.Module):
def __init__(self, dim, mlp_ratio=3, drop_path=0.):
super().__init__()
self.dwconv = ConvBN(dim, dim, 7, 1, (7 - 1) // 2, groups=dim, with_bn=True)
self.f1 = ConvBN(dim, mlp_ratio * dim, 1, with_bn=False)
self.f2 = ConvBN(dim, mlp_ratio * dim, 1, with_bn=False)
self.g = ConvBN(mlp_ratio * dim, dim, 1, with_bn=True)
self.dwconv2 = ConvBN(dim, dim, 7, 1, (7 - 1) // 2, groups=dim, with_bn=False)
self.act = nn.ReLU6()
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
input = x
x = self.dwconv(x)
x1, x2 = self.f1(x), self.f2(x)
x = self.act(x1) * x2
x = self.dwconv2(self.g(x))
x = input + self.drop_path(x)
return x
class C2f_StarNB(C2f):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(StarNetBlock(self.c) for _ in range(n))
2.2 修改task.py
1)首先进行注册
from ultralytics.nn.backbone.starnet import C2f_StarNB2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
C2f_StarNB
):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3,C2f_StarNB):
args.insert(2, n) # number of repeats
n = 1
2.3 yolov8-C2f_StarNB.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f_StarNB, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f_StarNB, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f_StarNB, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f_StarNB, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
你也可以替换neck部分的C2f