💡💡💡本文独家改进: CVPR2024 DCNv4结合YOLOv9 SPPELAN二次创新,结构图如下:
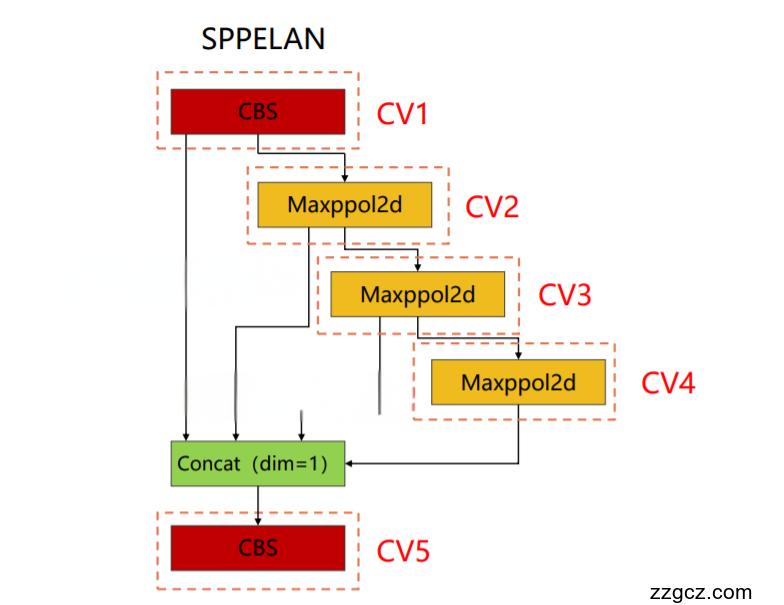
改进结构图:
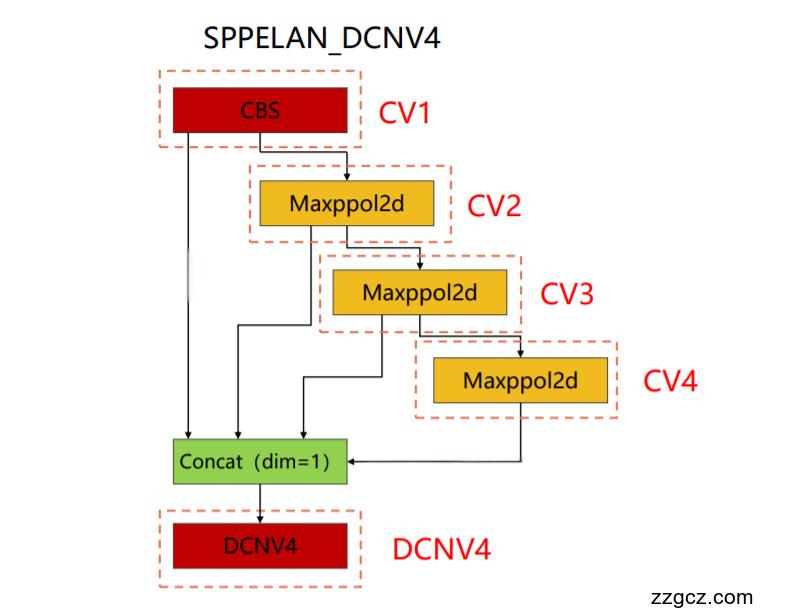
💡💡💡在多个私有数据集和公开数据集VisDrone2019、PASCAL VOC实现涨点
收录
YOLOv8原创自研
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.原理介绍
1.1 DCNv4介绍

论文: https://arxiv.org/pdf/2401.06197.pdf
摘要:我们介绍了可变形卷积v4 (DCNv4),这是一种高效的算子,专为广泛的视觉应用而设计。DCNv4通过两个关键增强解决了其前身DCNv3的局限性:去除空间聚合中的softmax归一化,增强空间聚合的动态性和表现力;优化内存访问以最小化冗余操作以提高速度。与DCNv3相比,这些改进显著加快了收敛速度,并大幅提高了处理速度,其中DCNv4的转发速度是DCNv3的三倍以上。DCNv4在各种任务中表现出卓越的性能,包括图像分类、实例和语义分割,尤其是图像生成。当在潜在扩散模型中与U-Net等生成模型集成时,DCNv4的性能优于其基线,强调了其增强生成模型的可能性。在实际应用中,将InternImage模型中的DCNv3替换为DCNv4来创建FlashInternImage,无需进一步修改即可使速度提高80%,并进一步提高性能。DCNv4在速度和效率方面的进步,以及它在不同视觉任务中的强大性能,显示了它作为未来视觉模型基础构建块的潜力。
图1所示。(a)我们以DCNv3为基准显示相对运行时间。DCNv4比DCNv3有明显的加速,并且超过了其他常见的视觉算子。(b)在相同的网络架构下,DCNv4收敛速度快于其他视觉算子,而DCNv3在初始训练阶段落后于视觉算子。

为了克服这些挑战,我们提出了可变形卷积v4 (DCNv4),这是一种创新的进步,用于优化稀疏DCN算子的实际效率。DCNv4具有更快的实现速度和改进的操作符设计,以增强其性能,我们将详细说明如下:
首先,我们对现有实现进行指令级内核分析,发现DCNv3已经是轻量级的。计算成本不到1%,而内存访问成本为99%。这促使我们重新审视运算符实现,并发现DCN转发过程中的许多内存访问是冗余的,因此可以进行优化,从而实现更快的DCNv4实现。
其次,从卷积的无界权值范围中得到启发,我们发现在DCNv3中,密集关注下的标准操作——空间聚合中的softmax归一化是不必要的,因为它不要求算子对每个位置都有专用的聚合窗口。直观地说,softmax将有界的0 ~ 1值范围放在权重上,并将限制聚合权重的表达能力。这一见解使我们消除了DCNv4中的softmax,增强了其动态特性并提高了其性能。
因此,DCNv4不仅收敛速度明显快于DCNv3,而且正向速度提高了3倍以上。这一改进使DCNv4能够充分利用其稀疏特性,成为最快的通用核心视觉算子之一。
我们进一步将InternImage中的DCNv3替换为DCNv4,创建FlashInternImage。值得注意的是,与InternImage相比,FlashInternImage在没有任何额外修改的情况下实现了50 ~ 80%的速度提升。这一增强定位FlashInternImage作为最快的现代视觉骨干网络之一,同时保持卓越的性能。在DCNv4的帮助下,FlashInternImage显著提高了ImageNet分类[10]和迁移学习设置的收敛速度,并进一步提高了下游任务的性能。
图2。(a)注意力(Attention)和(b) DCNv3使用有限的(范围从0 ~ 1)动态权值来聚合空间特征,而注意力的窗口(采样点集)是相同的,DCNv3为每个位置使用专用的窗口。(c)卷积对于聚合权值具有更灵活的无界值范围,并为每个位置使用专用滑动窗口,但窗口形状和聚合权值是与输入无关的。(d) DCNv4结合两者的优点,采用自适应聚合窗口和无界值范围的动态聚合权值。

1.2 YOLOv9原理介绍

论文: 2402.13616.pdf (arxiv.org)
代码:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information摘要: 如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。因此,YOLOv9 深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。作者提出了可编程梯度信息(programmable gradient information,PGI)的概念,来应对深度网络实现多个目标所需要的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了 PGI 可以在轻量级模型上取得优异的结果。研究者在基于 MS COCO 数据集的目标检测任务上验证所提出的 GELAN 和 PGI。结果表明,与其他 SOTA 方法相比,GELAN 仅使用传统卷积算子即可实现更好的参数利用率。对于 PGI 而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的 SOTA 模型获得更好的结果。对比结果如图1所示。

YOLOv9架构图(来自集智书童)

2.如何加入YOLOv8
2.1 DCNV4源码下载
下载链接:GitHub - OpenGVLab/DCNv4: [CVPR 2024] Deformable Convolution v4
将 DCNv4_op文件夹放入ultralytics\nn目录下

2.2 编译DCNv4
在DCNv4_op文件夹下执行以下命令:
python setup.py build install编译通过

2.3 新建ultralytics/nn/yolov9/yolov9.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from ultralytics.nn.modules.conv import Conv,autopad
class RepConvN(nn.Module):
"""RepConv is a basic rep-style block, including training and deploy status
This code is based on https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py
"""
default_act = nn.SiLU() # default activation
def __init__(self, c1, c2, k=3, s=1, p=1, g=1, d=1, act=True, bn=False, deploy=False):
super().__init__()
assert k == 3 and p == 1
self.g = g
self.c1 = c1
self.c2 = c2
self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
self.bn = None
self.conv1 = Conv(c1, c2, k, s, p=p, g=g, act=False)
self.conv2 = Conv(c1, c2, 1, s, p=(p - k // 2), g=g, act=False)
def forward_fuse(self, x):
"""Forward process"""
return self.act(self.conv(x))
def forward(self, x):
"""Forward process"""
if hasattr(self, 'conv'):
return self.forward_fuse(x)
id_out = 0 if self.bn is None else self.bn(x)
return self.act(self.conv1(x) + self.conv2(x) + id_out)
def get_equivalent_kernel_bias(self):
kernel3x3, bias3x3 = self._fuse_bn_tensor(self.conv1)
kernel1x1, bias1x1 = self._fuse_bn_tensor(self.conv2)
kernelid, biasid = self._fuse_bn_tensor(self.bn)
return kernel3x3 + self._pad_1x1_to_3x3_tensor(kernel1x1) + kernelid, bias3x3 + bias1x1 + biasid
def _avg_to_3x3_tensor(self, avgp):
channels = self.c1
groups = self.g
kernel_size = avgp.kernel_size
input_dim = channels // groups
k = torch.zeros((channels, input_dim, kernel_size, kernel_size))
k[np.arange(channels), np.tile(np.arange(input_dim), groups), :, :] = 1.0 / kernel_size ** 2
return k
def _pad_1x1_to_3x3_tensor(self, kernel1x1):
if kernel1x1 is None:
return 0
else:
return torch.nn.functional.pad(kernel1x1, [1, 1, 1, 1])
def _fuse_bn_tensor(self, branch):
if branch is None:
return 0, 0
if isinstance(branch, Conv):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
elif isinstance(branch, nn.BatchNorm2d):
if not hasattr(self, 'id_tensor'):
input_dim = self.c1 // self.g
kernel_value = np.zeros((self.c1, input_dim, 3, 3), dtype=np.float32)
for i in range(self.c1):
kernel_value[i, i % input_dim, 1, 1] = 1
self.id_tensor = torch.from_numpy(kernel_value).to(branch.weight.device)
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def switch_to_deploy(self):
if hasattr(self, 'conv'):
return
kernel, bias = self.get_equivalent_kernel_bias()
self.conv = nn.Conv2d(in_channels=self.conv1.conv.in_channels,
out_channels=self.conv1.conv.out_channels,
kernel_size=self.conv1.conv.kernel_size,
stride=self.conv1.conv.stride,
padding=self.conv1.conv.padding,
dilation=self.conv1.conv.dilation,
groups=self.conv1.conv.groups,
bias=True).requires_grad_(False)
self.conv.weight.data = kernel
self.conv.bias.data = bias
for para in self.parameters():
para.detach_()
self.__delattr__('conv1')
self.__delattr__('conv2')
if hasattr(self, 'nm'):
self.__delattr__('nm')
if hasattr(self, 'bn'):
self.__delattr__('bn')
if hasattr(self, 'id_tensor'):
self.__delattr__('id_tensor')
class RepNBottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, kernels, groups, expand
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = RepConvN(c1, c_, k[0], 1)
self.cv2 = Conv(c_, c2, k[1], 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
class RepNCSP(nn.Module):
# CSP Bottleneck with 3 convolutions
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)
self.m = nn.Sequential(*(RepNBottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
class RepNCSPELAN4(nn.Module):
# csp-elan
def __init__(self, c1, c2, c3, c4, c5=1): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = c3//2
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = nn.Sequential(RepNCSP(c3//2, c4, c5), Conv(c4, c4, 3, 1))
self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), Conv(c4, c4, 3, 1))
self.cv4 = Conv(c3+(2*c4), c2, 1, 1)
def forward(self, x):
y = list(self.cv1(x).chunk(2, 1))
y.extend((m(y[-1])) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
def forward_split(self, x):
y = list(self.cv1(x).split((self.c, self.c), 1))
y.extend(m(y[-1]) for m in [self.cv2, self.cv3])
return self.cv4(torch.cat(y, 1))
class ADown(nn.Module):
def __init__(self, c1, c2): # ch_in, ch_out, shortcut, kernels, groups, expand
super().__init__()
self.c = c2 // 2
self.cv1 = Conv(c1 // 2, self.c, 3, 2, 1)
self.cv2 = Conv(c1 // 2, self.c, 1, 1, 0)
def forward(self, x):
x = torch.nn.functional.avg_pool2d(x, 2, 1, 0, False, True)
x1,x2 = x.chunk(2, 1)
x1 = self.cv1(x1)
x2 = torch.nn.functional.max_pool2d(x2, 3, 2, 1)
x2 = self.cv2(x2)
return torch.cat((x1, x2), 1)
class CBLinear(nn.Module):
def __init__(self, c1, c2s, k=1, s=1, p=None, g=1): # ch_in, ch_outs, kernel, stride, padding, groups
super(CBLinear, self).__init__()
self.c2s = c2s
self.conv = nn.Conv2d(c1, sum(c2s), k, s, autopad(k, p), groups=g, bias=True)
def forward(self, x):
outs = self.conv(x).split(self.c2s, dim=1)
return outs
class CBFuse(nn.Module):
def __init__(self, idx):
super(CBFuse, self).__init__()
self.idx = idx
def forward(self, xs):
target_size = xs[-1].shape[2:]
res = [F.interpolate(x[self.idx[i]], size=target_size, mode='nearest') for i, x in enumerate(xs[:-1])]
out = torch.sum(torch.stack(res + xs[-1:]), dim=0)
return out
class Silence(nn.Module):
def __init__(self):
super(Silence, self).__init__()
def forward(self, x):
return x
##### GELAN #####
class SP(nn.Module):
def __init__(self, k=3, s=1):
super(SP, self).__init__()
self.m = nn.MaxPool2d(kernel_size=k, stride=s, padding=k // 2)
def forward(self, x):
return self.m(x)
class SPPELAN(nn.Module):
# spp-elan
def __init__(self, c1, c2, c3): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = c3
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = SP(5)
self.cv3 = SP(5)
self.cv4 = SP(5)
self.cv5 = Conv(4 * c3, c2, 1, 1)
def forward(self, x):
y = [self.cv1(x)]
y.extend(m(y[-1]) for m in [self.cv2, self.cv3, self.cv4])
return self.cv5(torch.cat(y, 1))
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.nn.modules import (Conv, Bottleneck)
try:
from DCNv4.modules.dcnv4 import DCNv4
except ImportError as e:
pass
def autopad(k, p=None, d=1): # kernel, padding, dilation
"""Pad to 'same' shape outputs."""
if d > 1:
k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
class DCNV4_YOLO(nn.Module):
def __init__(self, inc, ouc, k=1, s=1, p=None, g=1, d=1, act=True):
super().__init__()
if inc != ouc:
self.stem_conv = Conv(inc, ouc, k=1)
self.dcnv4 = DCNv4(ouc, kernel_size=k, stride=s, pad=autopad(k, p, d), group=g, dilation=d)
self.bn = nn.BatchNorm2d(ouc)
self.act = Conv.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()
def forward(self, x):
if hasattr(self, 'stem_conv'):
x = self.stem_conv(x)
x = self.dcnv4(x, (x.size(2), x.size(3)))
x = self.act(self.bn(x))
return x
class Bottleneck_DCNV4(Bottleneck):
"""Standard bottleneck with DCNV3."""
def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): # ch_in, ch_out, shortcut, groups, kernels, expand
super().__init__(c1, c2, shortcut, g, k, e)
c_ = int(c2 * e) # hidden channels
self.cv2 = DCNV4_YOLO(c_, c2, k[1])
class SPPELAN_DCNV4(nn.Module):
# spp-elan
def __init__(self, c1, c2, c3): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
self.c = c3
self.cv1 = Conv(c1, c3, 1, 1)
self.cv2 = SP(5)
self.cv3 = SP(5)
self.cv4 = SP(5)
self.cv5 = Conv(4 * c3, c2, 1, 1)
self.DCNV4 = Bottleneck_DCNV4(4 * c3, c2)
def forward(self, x):
y = [self.cv1(x)]
y.extend(m(y[-1]) for m in [self.cv2, self.cv3, self.cv4])
return self.DCNV4(torch.cat(y, 1))
2.4 注册ultralytics/nn/tasks.py
1)首先SPPELAN_DCNV4进行注册
from ultralytics.nn.yolov9 import SPPELAN_DCNV42)修改 def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
if m in (
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
SPPELAN_DCNV4
):3)修改class DetectionModel(BaseModel):
m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(1, ch, s, s))]) # forward修改为
self.model.to(torch.device('cuda'))
m.stride = torch.tensor(
[s / x.shape[-2] for x in forward(torch.zeros(2, ch, s, s).to(torch.device('cuda')))]) # forward2.5 dcnv4.py修改
dcnv4.py替换为以下内容
# --------------------------------------------------------
# Deformable Convolution v4
# Copyright (c) 2023 OpenGVLab
# Licensed under The MIT License [see LICENSE for details]
# --------------------------------------------------------
from __future__ import absolute_import
from __future__ import print_function
from __future__ import division
import math
import torch
from torch import nn
import torch.nn.functional as F
from torch.nn.init import xavier_uniform_, constant_
from ..functions import DCNv4Function
class CenterFeatureScaleModule(nn.Module):
def forward(self,
query,
center_feature_scale_proj_weight,
center_feature_scale_proj_bias):
center_feature_scale = F.linear(query,
weight=center_feature_scale_proj_weight,
bias=center_feature_scale_proj_bias).sigmoid()
return center_feature_scale
class DCNv4(nn.Module):
def __init__(
self,
channels=64,
kernel_size=3,
stride=1,
pad=1,
dilation=1,
group=4,
offset_scale=1.0,
dw_kernel_size=None,
center_feature_scale=False,
remove_center=False,
output_bias=True,
without_pointwise=False,
**kwargs):
"""
DCNv4 Module
:param channels
:param kernel_size
:param stride
:param pad
:param dilation
:param group
:param offset_scale
:param act_layer
:param norm_layer
"""
super().__init__()
if channels % group != 0:
raise ValueError(
f'channels must be divisible by group, but got {channels} and {group}')
_d_per_group = channels // group
# you'd better set _d_per_group to a power of 2 which is more efficient in our CUDA implementation
# assert _d_per_group % 16 == 0
self.offset_scale = offset_scale
self.channels = channels
self.kernel_size = kernel_size
self.stride = stride
self.dilation = dilation
self.pad = pad
self.group = group
self.group_channels = channels // group
self.offset_scale = offset_scale
self.dw_kernel_size = dw_kernel_size
self.center_feature_scale = center_feature_scale
self.remove_center = int(remove_center)
self.without_pointwise = without_pointwise
self.K = group * (kernel_size * kernel_size - self.remove_center)
if dw_kernel_size is not None:
self.offset_mask_dw = nn.Conv2d(channels, channels, dw_kernel_size, stride=1,
padding=(dw_kernel_size - 1) // 2, groups=channels)
self.offset_mask = nn.Linear(channels, int(math.ceil((self.K * 3) / 8) * 8))
if not without_pointwise:
self.value_proj = nn.Linear(channels, channels)
self.output_proj = nn.Linear(channels, channels, bias=output_bias)
self._reset_parameters()
if center_feature_scale:
self.center_feature_scale_proj_weight = nn.Parameter(
torch.zeros((group, channels), dtype=torch.float))
self.center_feature_scale_proj_bias = nn.Parameter(
torch.tensor(0.0, dtype=torch.float).view((1,)).repeat(group, ))
self.center_feature_scale_module = CenterFeatureScaleModule()
def _reset_parameters(self):
constant_(self.offset_mask.weight.data, 0.)
constant_(self.offset_mask.bias.data, 0.)
if not self.without_pointwise:
xavier_uniform_(self.value_proj.weight.data)
constant_(self.value_proj.bias.data, 0.)
xavier_uniform_(self.output_proj.weight.data)
if self.output_proj.bias is not None:
constant_(self.output_proj.bias.data, 0.)
def forward(self, input, shape=None):
"""
:param query (N, H, W, C)
:return output (N, H, W, C)
"""
# (N, C, H, W) -> (N, H * W, C)
input = input.reshape((input.size(0), input.size(1), input.size(2) * input.size(3))).transpose(2, 1)
N, L, C = input.shape
if shape is not None:
H, W = shape
else:
H, W = int(L ** 0.5), int(L ** 0.5)
x = input
if not self.without_pointwise:
x = self.value_proj(x)
x = x.reshape(N, H, W, -1)
if self.dw_kernel_size is not None:
offset_mask_input = self.offset_mask_dw(input.view(N, H, W, C).permute(0, 3, 1, 2))
offset_mask_input = offset_mask_input.permute(0, 2, 3, 1).view(N, L, C)
else:
offset_mask_input = input
offset_mask = self.offset_mask(offset_mask_input).reshape(N, H, W, -1)
x_proj = x
x = DCNv4Function.apply(
x, offset_mask,
self.kernel_size, self.kernel_size,
self.stride, self.stride,
self.pad, self.pad,
self.dilation, self.dilation,
self.group, self.group_channels,
self.offset_scale,
256,
self.remove_center
)
x = x.view(N, L // self.stride // self.stride, -1)
if self.center_feature_scale:
center_feature_scale = self.center_feature_scale_module(
x, self.center_feature_scale_proj_weight, self.center_feature_scale_proj_bias)
center_feature_scale = center_feature_scale[..., None].repeat(
1, 1, 1, 1, self.channels // self.group).flatten(-2)
x = x * (1 - center_feature_scale) + x_proj * center_feature_scale
if not self.without_pointwise:
x = self.output_proj(x)
return x.transpose(2, 1).reshape((N, C, H // self.stride, W // self.stride))2.3 yolov8-SPPELAN_DCNV4.yaml

# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPELAN_DCNV4, [1024, 512]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)