💡💡💡本文独家改进:CVPR2024 TransXNet助力检测,代替YOLOv8 Backbone
改进结构图如下:
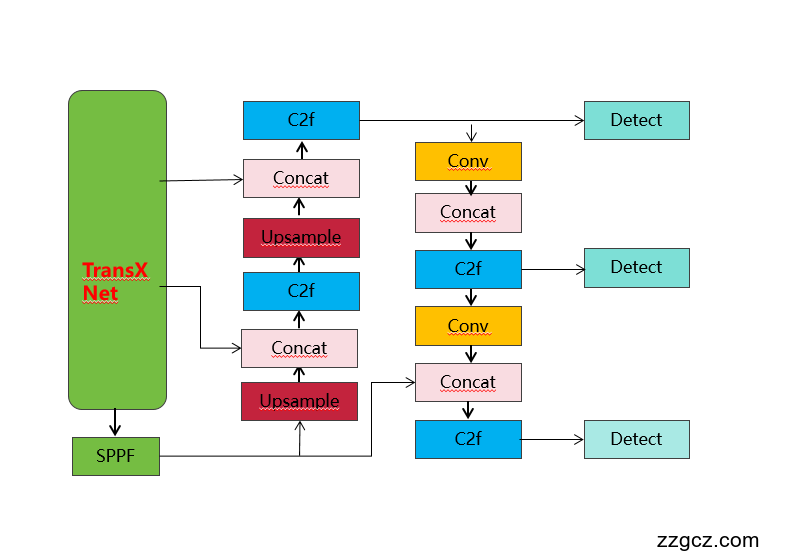
收录
YOLOv8原创自研
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.TransXNet原理介绍
 论文:
论文:问题点:
本文依旧从经典的 ViTs 说起,即基于 MHSA 构建远距离建模实现全局感受野的覆盖,但缺乏像 CNNs 般的归纳偏差能力。因此在泛化能力上相对较弱,需要大量的训练样本和数据增强策略来弥补。
本文:为了解决上述问题,这篇论文针对性地引入了一种新的混合网络模块,称为Dual Dynamic Token Mixer (D-Mixer),它以一种依赖于输入的方式聚合全局信息和局部细节。具体来说,输入特征被分成两部分,分别经过一个全局自注意力模块和一个依赖于输入的深度卷积模块进行处理,然后将两个输出连接在一起。这种简单的设计可以使网络同时看到全局和局部信息,从而增强了归纳偏差。论文中的实验证明,这种方法在感受野方面表现出色,即网络可以看到更广泛的上下文信息。

提出了一个轻量级的双动态token混频器(D-Mixer),它以一种依赖输入的方式聚合全局信息和局部细节。D-Mixer的工作原理是在均匀分割的特征段上分别应用高效的全局注意模块和输入依赖的深度卷积,从而赋予网络强大的归纳偏置和扩大的有效接受野。用D-Mixer作为基本构建块来设计TransXNet,这是一种新颖的混合CNN-Transformer视觉骨干网络。

如图1所示,提出的TransXNet采用了四个阶段的分层架构。每个阶段由一个patch嵌入层和几个顺序堆叠的块组成。使用7×7卷积层(步幅=4)实现第一个patch嵌入层,然后使用批归一化(BN),而其余阶段的patch嵌入层使用3×3卷积层(步幅=2)和BN。每个块由一个动态位置编码(DPE)层、一个双动态token混频器(D-Mixer)和一个多尺度前馈网络(MS-FFN)组成。

Overlapping Spatial Reduction Attention (OSRA)
空间降维注意(SRA)在前人的研究中得到了广泛的应用,利用稀疏标记区域关系高效提取全局信息。然而,为了减少标记计数而进行的非重叠空间缩减打破了patch边界附近的空间结构,降低了token的质量。为了解决这一问题,在SRA中引入了重叠空间缩减(OSR),通过使用更大的重叠斑块来更好地表示斑块边界附近的空间结构。在实践中,将OSR实例化为深度可分离卷积,其中步幅跟随PVT,内核大小等于步幅加3。

作者设计了一种像素聚焦注意力机制,它在每个Query附近具有细粒度的感知,同时同时保持全局信息的粗粒度意识。为了实现眼球运动中固有的像素级平移等价性,作者采用了一种双路径设计,包括以Query为中心的滑动窗口注意力和池化注意力。

理论部分详见:
TransNeXt:昨日最强模型已不强,TransNeXt-Tiny在ImageNet上准确率刷到84.0% - 知乎 (zhihu.com)
2. TransXNet加入YOLOv8
TransNeXt文件夹内容如下:

2.1 新建ultralytics/nn/backbone/TransNeXt/transnext_cuda.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
import math
import swattention
__all__ = ['transnext_micro', 'transnext_tiny', 'transnext_small', 'transnext_base', 'AggregatedAttention',
'get_relative_position_cpb']
CUDA_NUM_THREADS = 128
class sw_qkrpb_cuda(torch.autograd.Function):
@staticmethod
def forward(ctx, query, key, rpb, height, width, kernel_size):
attn_weight = swattention.qk_rpb_forward(query, key, rpb, height, width, kernel_size, CUDA_NUM_THREADS)
ctx.save_for_backward(query, key)
ctx.height, ctx.width, ctx.kernel_size = height, width, kernel_size
return attn_weight
@staticmethod
def backward(ctx, d_attn_weight):
query, key = ctx.saved_tensors
height, width, kernel_size = ctx.height, ctx.width, ctx.kernel_size
d_query, d_key, d_rpb = swattention.qk_rpb_backward(d_attn_weight.contiguous(), query, key, height, width,
kernel_size, CUDA_NUM_THREADS)
return d_query, d_key, d_rpb, None, None, None
class sw_av_cuda(torch.autograd.Function):
@staticmethod
def forward(ctx, attn_weight, value, height, width, kernel_size):
output = swattention.av_forward(attn_weight, value, height, width, kernel_size, CUDA_NUM_THREADS)
ctx.save_for_backward(attn_weight, value)
ctx.height, ctx.width, ctx.kernel_size = height, width, kernel_size
return output
@staticmethod
def backward(ctx, d_output):
attn_weight, value = ctx.saved_tensors
height, width, kernel_size = ctx.height, ctx.width, ctx.kernel_size
d_attn_weight, d_value = swattention.av_backward(d_output.contiguous(), attn_weight, value, height, width,
kernel_size, CUDA_NUM_THREADS)
return d_attn_weight, d_value, None, None, None
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, bias=True, groups=dim)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W).contiguous()
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2)
return x
class ConvolutionalGLU(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
hidden_features = int(2 * hidden_features / 3)
self.fc1 = nn.Linear(in_features, hidden_features * 2)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x, H, W):
x, v = self.fc1(x).chunk(2, dim=-1)
x = self.act(self.dwconv(x, H, W)) * v
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
@torch.no_grad()
def get_relative_position_cpb(query_size, key_size, pretrain_size=None):
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pretrain_size = pretrain_size or query_size
axis_qh = torch.arange(query_size[0], dtype=torch.float32)
axis_kh = F.adaptive_avg_pool1d(axis_qh.unsqueeze(0), key_size[0]).squeeze(0)
axis_qw = torch.arange(query_size[1], dtype=torch.float32)
axis_kw = F.adaptive_avg_pool1d(axis_qw.unsqueeze(0), key_size[1]).squeeze(0)
axis_kh, axis_kw = torch.meshgrid(axis_kh, axis_kw)
axis_qh, axis_qw = torch.meshgrid(axis_qh, axis_qw)
axis_kh = torch.reshape(axis_kh, [-1])
axis_kw = torch.reshape(axis_kw, [-1])
axis_qh = torch.reshape(axis_qh, [-1])
axis_qw = torch.reshape(axis_qw, [-1])
relative_h = (axis_qh[:, None] - axis_kh[None, :]) / (pretrain_size[0] - 1) * 8
relative_w = (axis_qw[:, None] - axis_kw[None, :]) / (pretrain_size[1] - 1) * 8
relative_hw = torch.stack([relative_h, relative_w], dim=-1).view(-1, 2)
relative_coords_table, idx_map = torch.unique(relative_hw, return_inverse=True, dim=0)
relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
torch.abs(relative_coords_table) + 1.0) / torch.log2(torch.tensor(8, dtype=torch.float32))
return idx_map, relative_coords_table
@torch.no_grad()
def get_seqlen_scale(input_resolution, window_size):
return torch.nn.functional.avg_pool2d(torch.ones(1, input_resolution[0], input_resolution[1]) * (window_size ** 2),
window_size, stride=1, padding=window_size // 2, ).reshape(-1, 1)
class AggregatedAttention(nn.Module):
def __init__(self, dim, input_resolution, num_heads=8, window_size=3, qkv_bias=True,
attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.sr_ratio = sr_ratio
assert window_size % 2 == 1, "window size must be odd"
self.window_size = window_size
self.local_len = window_size ** 2
self.pool_H, self.pool_W = input_resolution[0] // self.sr_ratio, input_resolution[1] // self.sr_ratio
self.pool_len = self.pool_H * self.pool_W
self.unfold = nn.Unfold(kernel_size=window_size, padding=window_size // 2, stride=1)
self.temperature = nn.Parameter(
torch.log((torch.ones(num_heads, 1, 1) / 0.24).exp() - 1)) # Initialize softplus(temperature) to 1/0.24.
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.query_embedding = nn.Parameter(
nn.init.trunc_normal_(torch.empty(self.num_heads, 1, self.head_dim), mean=0, std=0.02))
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# Components to generate pooled features.
self.pool = nn.AdaptiveAvgPool2d((self.pool_H, self.pool_W))
self.sr = nn.Conv2d(dim, dim, kernel_size=1, stride=1, padding=0)
self.norm = nn.LayerNorm(dim)
self.act = nn.GELU()
# mlp to generate continuous relative position bias
self.cpb_fc1 = nn.Linear(2, 512, bias=True)
self.cpb_act = nn.ReLU(inplace=True)
self.cpb_fc2 = nn.Linear(512, num_heads, bias=True)
# relative bias for local features
self.relative_pos_bias_local = nn.Parameter(
nn.init.trunc_normal_(torch.empty(num_heads, self.local_len), mean=0, std=0.0004))
# Generate padding_mask && sequnce length scale
local_seq_length = get_seqlen_scale(input_resolution, window_size)
self.register_buffer("seq_length_scale", torch.as_tensor(np.log(local_seq_length.numpy() + self.pool_len)),
persistent=False)
# dynamic_local_bias:
self.learnable_tokens = nn.Parameter(
nn.init.trunc_normal_(torch.empty(num_heads, self.head_dim, self.local_len), mean=0, std=0.02))
self.learnable_bias = nn.Parameter(torch.zeros(num_heads, 1, self.local_len))
def forward(self, x, H, W, relative_pos_index, relative_coords_table):
B, N, C = x.shape
# Generate queries, normalize them with L2, add query embedding, and then magnify with sequence length scale and temperature.
# Use softplus function ensuring that the temperature is not lower than 0.
q_norm = F.normalize(self.q(x).reshape(B, N, self.num_heads, self.head_dim).permute(0, 2, 1, 3), dim=-1)
q_norm_scaled = (q_norm + self.query_embedding) * F.softplus(self.temperature) * self.seq_length_scale
# Generate unfolded keys and values and l2-normalize them
k_local, v_local = self.kv(x).reshape(B, N, 2 * self.num_heads, self.head_dim).permute(0, 2, 1, 3).chunk(2,
dim=1)
# Compute local similarity
attn_local = sw_qkrpb_cuda.apply(q_norm_scaled.contiguous(), F.normalize(k_local, dim=-1).contiguous(),
self.relative_pos_bias_local,
H, W, self.window_size)
# Generate pooled features
x_ = x.permute(0, 2, 1).reshape(B, -1, H, W).contiguous()
x_ = self.pool(self.act(self.sr(x_))).reshape(B, -1, self.pool_len).permute(0, 2, 1)
x_ = self.norm(x_)
# Generate pooled keys and values
kv_pool = self.kv(x_).reshape(B, self.pool_len, 2 * self.num_heads, self.head_dim).permute(0, 2, 1, 3)
k_pool, v_pool = kv_pool.chunk(2, dim=1)
# Use MLP to generate continuous relative positional bias for pooled features.
pool_bias = self.cpb_fc2(self.cpb_act(self.cpb_fc1(relative_coords_table))).transpose(0, 1)[:,
relative_pos_index.view(-1)].view(-1, N, self.pool_len)
# Compute pooled similarity
attn_pool = q_norm_scaled @ F.normalize(k_pool, dim=-1).transpose(-2, -1) + pool_bias
# Concatenate local & pooled similarity matrices and calculate attention weights through the same Softmax
attn = torch.cat([attn_local, attn_pool], dim=-1).softmax(dim=-1)
attn = self.attn_drop(attn)
# Split the attention weights and separately aggregate the values of local & pooled features
attn_local, attn_pool = torch.split(attn, [self.local_len, self.pool_len], dim=-1)
attn_local = (q_norm @ self.learnable_tokens) + self.learnable_bias + attn_local
x_local = sw_av_cuda.apply(attn_local.type_as(v_local), v_local.contiguous(), H, W, self.window_size)
x_pool = attn_pool @ v_pool
x = (x_local + x_pool).transpose(1, 2).reshape(B, N, C)
# Linear projection and output
x = self.proj(x)
x = self.proj_drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, input_resolution, num_heads=8, qkv_bias=True, attn_drop=0.,
proj_drop=0.):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.temperature = nn.Parameter(
torch.log((torch.ones(num_heads, 1, 1) / 0.24).exp() - 1)) # Initialize softplus(temperature) to 1/0.24.
# Generate sequnce length scale
self.register_buffer("seq_length_scale", torch.as_tensor(np.log(input_resolution[0] * input_resolution[1])),
persistent=False)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.query_embedding = nn.Parameter(
nn.init.trunc_normal_(torch.empty(self.num_heads, 1, self.head_dim), mean=0, std=0.02))
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# mlp to generate continuous relative position bias
self.cpb_fc1 = nn.Linear(2, 512, bias=True)
self.cpb_act = nn.ReLU(inplace=True)
self.cpb_fc2 = nn.Linear(512, num_heads, bias=True)
def forward(self, x, H, W, relative_pos_index, relative_coords_table):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, -1, 3 * self.num_heads, self.head_dim).permute(0, 2, 1, 3)
q, k, v = qkv.chunk(3, dim=1)
# Use MLP to generate continuous relative positional bias
rel_bias = self.cpb_fc2(self.cpb_act(self.cpb_fc1(relative_coords_table))).transpose(0, 1)[:,
relative_pos_index.view(-1)].view(-1, N, N)
# Calculate attention map using sequence length scaled cosine attention and query embedding
attn = ((F.normalize(q, dim=-1) + self.query_embedding) * F.softplus(
self.temperature) * self.seq_length_scale) @ F.normalize(k, dim=-1).transpose(-2, -1) + rel_bias
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, input_resolution, window_size=3, mlp_ratio=4.,
qkv_bias=False, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
if sr_ratio == 1:
self.attn = Attention(
dim,
input_resolution,
num_heads=num_heads,
qkv_bias=qkv_bias,
attn_drop=attn_drop,
proj_drop=drop)
else:
self.attn = AggregatedAttention(
dim,
input_resolution,
window_size=window_size,
num_heads=num_heads,
qkv_bias=qkv_bias,
attn_drop=attn_drop,
proj_drop=drop,
sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = ConvolutionalGLU(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x, H, W, relative_pos_index, relative_coords_table):
x = x + self.drop_path(self.attn(self.norm1(x), H, W, relative_pos_index, relative_coords_table))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x
class OverlapPatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, patch_size=7, stride=4, in_chans=3, embed_dim=768):
super().__init__()
patch_size = to_2tuple(patch_size)
assert max(patch_size) > stride, "Set larger patch_size than stride"
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride,
padding=(patch_size[0] // 2, patch_size[1] // 2))
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
x = self.proj(x)
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
class TransNeXt(nn.Module):
'''
The parameter "img size" is primarily utilized for generating relative spatial coordinates,
which are used to compute continuous relative positional biases. As this TransNeXt implementation does not support multi-scale inputs,
it is recommended to set the "img size" parameter to a value that is exactly the same as the resolution of the inference images.
It is not advisable to set the "img size" parameter to a value exceeding 800x800.
The "pretrain size" refers to the "img size" used during the initial pre-training phase,
which is used to scale the relative spatial coordinates for better extrapolation by the MLP.
For models trained on ImageNet-1K at a resolution of 224x224,
as well as downstream task models fine-tuned based on these pre-trained weights,
the "pretrain size" parameter should be set to 224x224.
'''
def __init__(self, img_size=640, pretrain_size=None, window_size=[3, 3, 3, None],
patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], num_stages=4):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
pretrain_size = pretrain_size or img_size
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
# Generate relative positional coordinate table and index for each stage to compute continuous relative positional bias.
relative_pos_index, relative_coords_table = get_relative_position_cpb(
query_size=to_2tuple(img_size // (2 ** (i + 2))),
key_size=to_2tuple(img_size // (2 ** (num_stages + 1))),
pretrain_size=to_2tuple(pretrain_size // (2 ** (i + 2))))
self.register_buffer(f"relative_pos_index{i + 1}", relative_pos_index, persistent=False)
self.register_buffer(f"relative_coords_table{i + 1}", relative_coords_table, persistent=False)
patch_embed = OverlapPatchEmbed(patch_size=patch_size * 2 - 1 if i == 0 else 3,
stride=patch_size if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i])
block = nn.ModuleList([Block(
dim=embed_dims[i], input_resolution=to_2tuple(img_size // (2 ** (i + 2))), window_size=window_size[i],
num_heads=num_heads[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + j], norm_layer=norm_layer,
sr_ratio=sr_ratios[i])
for j in range(depths[i])])
norm = norm_layer(embed_dims[i])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"block{i + 1}", block)
setattr(self, f"norm{i + 1}", norm)
for n, m in self.named_modules():
self._init_weights(m, n)
self.to(torch.device('cuda'))
self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640).to(torch.device('cuda')))]
def _init_weights(self, m: nn.Module, name: str = ''):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, (nn.LayerNorm, nn.GroupNorm, nn.BatchNorm2d)):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
def forward(self, x):
B = x.shape[0]
feature = []
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
block = getattr(self, f"block{i + 1}")
norm = getattr(self, f"norm{i + 1}")
x, H, W = patch_embed(x)
relative_pos_index = getattr(self, f"relative_pos_index{i + 1}")
relative_coords_table = getattr(self, f"relative_coords_table{i + 1}")
for blk in block:
x = blk(x, H, W, relative_pos_index.to(x.device), relative_coords_table.to(x.device))
x = norm(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
feature.append(x)
return feature
def transnext_micro(pretrained=False, **kwargs):
model = TransNeXt(window_size=[3, 3, 3, None],
patch_size=4, embed_dims=[48, 96, 192, 384], num_heads=[2, 4, 8, 16],
mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 15, 2], sr_ratios=[8, 4, 2, 1],
**kwargs)
return model
def transnext_tiny(pretrained=False, **kwargs):
model = TransNeXt(window_size=[3, 3, 3, None],
patch_size=4, embed_dims=[72, 144, 288, 576], num_heads=[3, 6, 12, 24],
mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 15, 2], sr_ratios=[8, 4, 2, 1],
**kwargs)
return model
def transnext_small(pretrained=False, **kwargs):
model = TransNeXt(window_size=[3, 3, 3, None],
patch_size=4, embed_dims=[72, 144, 288, 576], num_heads=[3, 6, 12, 24],
mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[5, 5, 22, 5], sr_ratios=[8, 4, 2, 1],
**kwargs)
return model
def transnext_base(pretrained=False, **kwargs):
model = TransNeXt(window_size=[3, 3, 3, None],
patch_size=4, embed_dims=[96, 192, 384, 768], num_heads=[4, 8, 16, 32],
mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[5, 5, 23, 5], sr_ratios=[8, 4, 2, 1],
**kwargs)
return model2.2 新建ultralytics/nn/backbone/TransNeXt/transnext_native.py
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from functools import partial
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
import math
__all__ = ['transnext_micro', 'transnext_tiny', 'transnext_small', 'transnext_base', 'AggregatedAttention',
'get_relative_position_cpb']
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, kernel_size=3, stride=1, padding=1, bias=True, groups=dim)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W).contiguous()
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2)
return x
class ConvolutionalGLU(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
hidden_features = int(2 * hidden_features / 3)
self.fc1 = nn.Linear(in_features, hidden_features * 2)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
def forward(self, x, H, W):
x, v = self.fc1(x).chunk(2, dim=-1)
x = self.act(self.dwconv(x, H, W)) * v
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
@torch.no_grad()
def get_relative_position_cpb(query_size, key_size, pretrain_size=None):
# device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
pretrain_size = pretrain_size or query_size
axis_qh = torch.arange(query_size[0], dtype=torch.float32)
axis_kh = F.adaptive_avg_pool1d(axis_qh.unsqueeze(0), key_size[0]).squeeze(0)
axis_qw = torch.arange(query_size[1], dtype=torch.float32)
axis_kw = F.adaptive_avg_pool1d(axis_qw.unsqueeze(0), key_size[1]).squeeze(0)
axis_kh, axis_kw = torch.meshgrid(axis_kh, axis_kw)
axis_qh, axis_qw = torch.meshgrid(axis_qh, axis_qw)
axis_kh = torch.reshape(axis_kh, [-1])
axis_kw = torch.reshape(axis_kw, [-1])
axis_qh = torch.reshape(axis_qh, [-1])
axis_qw = torch.reshape(axis_qw, [-1])
relative_h = (axis_qh[:, None] - axis_kh[None, :]) / (pretrain_size[0] - 1) * 8
relative_w = (axis_qw[:, None] - axis_kw[None, :]) / (pretrain_size[1] - 1) * 8
relative_hw = torch.stack([relative_h, relative_w], dim=-1).view(-1, 2)
relative_coords_table, idx_map = torch.unique(relative_hw, return_inverse=True, dim=0)
relative_coords_table = torch.sign(relative_coords_table) * torch.log2(
torch.abs(relative_coords_table) + 1.0) / torch.log2(torch.tensor(8, dtype=torch.float32))
return idx_map, relative_coords_table
@torch.no_grad()
def get_seqlen_and_mask(input_resolution, window_size):
attn_map = F.unfold(torch.ones([1, 1, input_resolution[0], input_resolution[1]]), window_size,
dilation=1, padding=(window_size // 2, window_size // 2), stride=1)
attn_local_length = attn_map.sum(-2).squeeze().unsqueeze(-1)
attn_mask = (attn_map.squeeze(0).permute(1, 0)) == 0
return attn_local_length, attn_mask
class AggregatedAttention(nn.Module):
def __init__(self, dim, input_resolution, num_heads=8, window_size=3, qkv_bias=True,
attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.sr_ratio = sr_ratio
assert window_size % 2 == 1, "window size must be odd"
self.window_size = window_size
self.local_len = window_size ** 2
self.pool_H, self.pool_W = input_resolution[0] // self.sr_ratio, input_resolution[1] // self.sr_ratio
self.pool_len = self.pool_H * self.pool_W
self.unfold = nn.Unfold(kernel_size=window_size, padding=window_size // 2, stride=1)
self.temperature = nn.Parameter(
torch.log((torch.ones(num_heads, 1, 1) / 0.24).exp() - 1)) # Initialize softplus(temperature) to 1/0.24.
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.query_embedding = nn.Parameter(
nn.init.trunc_normal_(torch.empty(self.num_heads, 1, self.head_dim), mean=0, std=0.02))
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# Components to generate pooled features.
self.pool = nn.AdaptiveAvgPool2d((self.pool_H, self.pool_W))
self.sr = nn.Conv2d(dim, dim, kernel_size=1, stride=1, padding=0)
self.norm = nn.LayerNorm(dim)
self.act = nn.GELU()
# mlp to generate continuous relative position bias
self.cpb_fc1 = nn.Linear(2, 512, bias=True)
self.cpb_act = nn.ReLU(inplace=True)
self.cpb_fc2 = nn.Linear(512, num_heads, bias=True)
# relative bias for local features
self.relative_pos_bias_local = nn.Parameter(
nn.init.trunc_normal_(torch.empty(num_heads, self.local_len), mean=0,
std=0.0004))
# Generate padding_mask && sequnce length scale
local_seq_length, padding_mask = get_seqlen_and_mask(input_resolution, window_size)
self.register_buffer("seq_length_scale", torch.as_tensor(np.log(local_seq_length.numpy() + self.pool_len)),
persistent=False)
self.register_buffer("padding_mask", padding_mask, persistent=False)
# dynamic_local_bias:
self.learnable_tokens = nn.Parameter(
nn.init.trunc_normal_(torch.empty(num_heads, self.head_dim, self.local_len), mean=0, std=0.02))
self.learnable_bias = nn.Parameter(torch.zeros(num_heads, 1, self.local_len))
def forward(self, x, H, W, relative_pos_index, relative_coords_table):
B, N, C = x.shape
# Generate queries, normalize them with L2, add query embedding, and then magnify with sequence length scale and temperature.
# Use softplus function ensuring that the temperature is not lower than 0.
q_norm = F.normalize(self.q(x).reshape(B, N, self.num_heads, self.head_dim).permute(0, 2, 1, 3), dim=-1)
q_norm_scaled = (q_norm + self.query_embedding) * F.softplus(self.temperature) * self.seq_length_scale
# Generate unfolded keys and values and l2-normalize them
k_local, v_local = self.kv(x).chunk(2, dim=-1)
k_local = F.normalize(k_local.reshape(B, N, self.num_heads, self.head_dim), dim=-1).reshape(B, N, -1)
kv_local = torch.cat([k_local, v_local], dim=-1).permute(0, 2, 1).reshape(B, -1, H, W)
k_local, v_local = self.unfold(kv_local).reshape(
B, 2 * self.num_heads, self.head_dim, self.local_len, N).permute(0, 1, 4, 2, 3).chunk(2, dim=1)
# Compute local similarity
attn_local = ((q_norm_scaled.unsqueeze(-2) @ k_local).squeeze(-2) \
+ self.relative_pos_bias_local.unsqueeze(1)).masked_fill(self.padding_mask, float('-inf'))
# Generate pooled features
x_ = x.permute(0, 2, 1).reshape(B, -1, H, W).contiguous()
x_ = self.pool(self.act(self.sr(x_))).reshape(B, -1, self.pool_len).permute(0, 2, 1)
x_ = self.norm(x_)
# Generate pooled keys and values
kv_pool = self.kv(x_).reshape(B, self.pool_len, 2 * self.num_heads, self.head_dim).permute(0, 2, 1, 3)
k_pool, v_pool = kv_pool.chunk(2, dim=1)
# Use MLP to generate continuous relative positional bias for pooled features.
pool_bias = self.cpb_fc2(self.cpb_act(self.cpb_fc1(relative_coords_table))).transpose(0, 1)[:,
relative_pos_index.view(-1)].view(-1, N, self.pool_len)
# Compute pooled similarity
attn_pool = q_norm_scaled @ F.normalize(k_pool, dim=-1).transpose(-2, -1) + pool_bias
# Concatenate local & pooled similarity matrices and calculate attention weights through the same Softmax
attn = torch.cat([attn_local, attn_pool], dim=-1).softmax(dim=-1)
attn = self.attn_drop(attn)
# Split the attention weights and separately aggregate the values of local & pooled features
attn_local, attn_pool = torch.split(attn, [self.local_len, self.pool_len], dim=-1)
x_local = (((q_norm @ self.learnable_tokens) + self.learnable_bias + attn_local).unsqueeze(
-2) @ v_local.transpose(-2, -1)).squeeze(-2)
x_pool = attn_pool @ v_pool
x = (x_local + x_pool).transpose(1, 2).reshape(B, N, C)
# Linear projection and output
x = self.proj(x)
x = self.proj_drop(x)
return x
class Attention(nn.Module):
def __init__(self, dim, input_resolution, num_heads=8, qkv_bias=True, attn_drop=0., proj_drop=0.):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
self.head_dim = dim // num_heads
self.temperature = nn.Parameter(
torch.log((torch.ones(num_heads, 1, 1) / 0.24).exp() - 1)) # Initialize softplus(temperature) to 1/0.24.
# Generate sequnce length scale
self.register_buffer("seq_length_scale", torch.as_tensor(np.log(input_resolution[0] * input_resolution[1])),
persistent=False)
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.query_embedding = nn.Parameter(
nn.init.trunc_normal_(torch.empty(self.num_heads, 1, self.head_dim), mean=0, std=0.02))
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
# mlp to generate continuous relative position bias
self.cpb_fc1 = nn.Linear(2, 512, bias=True)
self.cpb_act = nn.ReLU(inplace=True)
self.cpb_fc2 = nn.Linear(512, num_heads, bias=True)
def forward(self, x, H, W, relative_pos_index, relative_coords_table):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, -1, 3 * self.num_heads, self.head_dim).permute(0, 2, 1, 3)
q, k, v = qkv.chunk(3, dim=1)
# Use MLP to generate continuous relative positional bias
rel_bias = self.cpb_fc2(self.cpb_act(self.cpb_fc1(relative_coords_table))).transpose(0, 1)[:,
relative_pos_index.view(-1)].view(-1, N, N)
# Calculate attention map using sequence length scaled cosine attention and query embedding
attn = ((F.normalize(q, dim=-1) + self.query_embedding) * F.softplus(
self.temperature) * self.seq_length_scale) @ F.normalize(k, dim=-1).transpose(-2, -1) + rel_bias
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
class Block(nn.Module):
def __init__(self, dim, num_heads, input_resolution, window_size=3, mlp_ratio=4.,
qkv_bias=False, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
if sr_ratio == 1:
self.attn = Attention(
dim,
input_resolution,
num_heads=num_heads,
qkv_bias=qkv_bias,
attn_drop=attn_drop,
proj_drop=drop)
else:
self.attn = AggregatedAttention(
dim,
input_resolution,
window_size=window_size,
num_heads=num_heads,
qkv_bias=qkv_bias,
attn_drop=attn_drop,
proj_drop=drop,
sr_ratio=sr_ratio)
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = ConvolutionalGLU(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x, H, W, relative_pos_index, relative_coords_table):
x = x + self.drop_path(self.attn(self.norm1(x), H, W, relative_pos_index, relative_coords_table))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x
class OverlapPatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, patch_size=7, stride=4, in_chans=3, embed_dim=768):
super().__init__()
patch_size = to_2tuple(patch_size)
assert max(patch_size) > stride, "Set larger patch_size than stride"
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride,
padding=(patch_size[0] // 2, patch_size[1] // 2))
self.norm = nn.LayerNorm(embed_dim)
def forward(self, x):
x = self.proj(x)
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
class TransNeXt(nn.Module):
'''
The parameter "img size" is primarily utilized for generating relative spatial coordinates,
which are used to compute continuous relative positional biases. As this TransNeXt implementation does not support multi-scale inputs,
it is recommended to set the "img size" parameter to a value that is exactly the same as the resolution of the inference images.
It is not advisable to set the "img size" parameter to a value exceeding 800x800.
The "pretrain size" refers to the "img size" used during the initial pre-training phase,
which is used to scale the relative spatial coordinates for better extrapolation by the MLP.
For models trained on ImageNet-1K at a resolution of 224x224,
as well as downstream task models fine-tuned based on these pre-trained weights,
the "pretrain size" parameter should be set to 224x224.
'''
def __init__(self, img_size=640, pretrain_size=None, window_size=[3, 3, 3, None],
patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1], num_stages=4):
super().__init__()
self.num_classes = num_classes
self.depths = depths
self.num_stages = num_stages
pretrain_size = pretrain_size or img_size
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
for i in range(num_stages):
# Generate relative positional coordinate table and index for each stage to compute continuous relative positional bias.
relative_pos_index, relative_coords_table = get_relative_position_cpb(
query_size=to_2tuple(img_size // (2 ** (i + 2))),
key_size=to_2tuple(img_size // (2 ** (num_stages + 1))),
pretrain_size=to_2tuple(pretrain_size // (2 ** (i + 2))))
self.register_buffer(f"relative_pos_index{i + 1}", relative_pos_index, persistent=False)
self.register_buffer(f"relative_coords_table{i + 1}", relative_coords_table, persistent=False)
patch_embed = OverlapPatchEmbed(patch_size=patch_size * 2 - 1 if i == 0 else 3,
stride=patch_size if i == 0 else 2,
in_chans=in_chans if i == 0 else embed_dims[i - 1],
embed_dim=embed_dims[i])
block = nn.ModuleList([Block(
dim=embed_dims[i], input_resolution=to_2tuple(img_size // (2 ** (i + 2))), window_size=window_size[i],
num_heads=num_heads[i], mlp_ratio=mlp_ratios[i], qkv_bias=qkv_bias,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + j], norm_layer=norm_layer,
sr_ratio=sr_ratios[i])
for j in range(depths[i])])
norm = norm_layer(embed_dims[i])
cur += depths[i]
setattr(self, f"patch_embed{i + 1}", patch_embed)
setattr(self, f"block{i + 1}", block)
setattr(self, f"norm{i + 1}", norm)
for n, m in self.named_modules():
self._init_weights(m, n)
self.channel = [i.size(1) for i in self.forward(torch.randn(1, 3, 640, 640))]
def _init_weights(self, m: nn.Module, name: str = ''):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, (nn.LayerNorm, nn.GroupNorm, nn.BatchNorm2d)):
nn.init.zeros_(m.bias)
nn.init.ones_(m.weight)
def forward(self, x):
B = x.shape[0]
feature = []
for i in range(self.num_stages):
patch_embed = getattr(self, f"patch_embed{i + 1}")
block = getattr(self, f"block{i + 1}")
norm = getattr(self, f"norm{i + 1}")
x, H, W = patch_embed(x)
relative_pos_index = getattr(self, f"relative_pos_index{i + 1}")
relative_coords_table = getattr(self, f"relative_coords_table{i + 1}")
for blk in block:
x = blk(x, H, W, relative_pos_index.to(x.device), relative_coords_table.to(x.device))
x = norm(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
feature.append(x)
return feature
def transnext_micro(pretrained=False, **kwargs):
model = TransNeXt(window_size=[3, 3, 3, None],
patch_size=4, embed_dims=[48, 96, 192, 384], num_heads=[2, 4, 8, 16],
mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 15, 2], sr_ratios=[8, 4, 2, 1],
**kwargs)
return model
def transnext_tiny(pretrained=False, **kwargs):
model = TransNeXt(window_size=[3, 3, 3, None],
patch_size=4, embed_dims=[72, 144, 288, 576], num_heads=[3, 6, 12, 24],
mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[2, 2, 15, 2], sr_ratios=[8, 4, 2, 1],
**kwargs)
return model
def transnext_small(pretrained=False, **kwargs):
model = TransNeXt(window_size=[3, 3, 3, None],
patch_size=4, embed_dims=[72, 144, 288, 576], num_heads=[3, 6, 12, 24],
mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[5, 5, 22, 5], sr_ratios=[8, 4, 2, 1],
**kwargs)
return model
def transnext_base(pretrained=False, **kwargs):
model = TransNeXt(window_size=[3, 3, 3, None],
patch_size=4, embed_dims=[96, 192, 384, 768], num_heads=[4, 8, 16, 32],
mlp_ratios=[8, 8, 4, 4], qkv_bias=True,
norm_layer=partial(nn.LayerNorm, eps=1e-6), depths=[5, 5, 23, 5], sr_ratios=[8, 4, 2, 1],
**kwargs)
return model
if __name__ == '__main__':
model = transnext_micro()
inputs = torch.randn((1, 3, 640, 640))
res = model(inputs)
for i in res:
print(i.size())2.3修改task.py
1)首先进行注册
try:
import swattention
from models.backbone.TransNeXt.transnext_cuda import *
except ImportError as e:
from models.backbone.TransNeXt.transnext_native import *
pass
2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
建议直接替换
def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
"""Parse a YOLO model.yaml dictionary into a PyTorch model."""
import ast
# Args
max_channels = float("inf")
nc, act, scales = (d.get(x) for x in ("nc", "activation", "scales"))
depth, width, kpt_shape = (d.get(x, 1.0) for x in ("depth_multiple", "width_multiple", "kpt_shape"))
if scales:
scale = d.get("scale")
if not scale:
scale = tuple(scales.keys())[0]
LOGGER.warning(f"WARNING ⚠️ no model scale passed. Assuming scale='{scale}'.")
depth, width, max_channels = scales[scale]
if act:
Conv.default_act = eval(act) # redefine default activation, i.e. Conv.default_act = nn.SiLU()
if verbose:
LOGGER.info(f"{colorstr('activation:')} {act}") # print
if verbose:
LOGGER.info(f"\n{'':>3}{'from':>20}{'n':>3}{'params':>10} {'module':<45}{'arguments':<30}")
ch = [ch]
layers, save, c2 = [], [], ch[-1] # layers, savelist, ch out
is_backbone = False
for i, (f, n, m, args) in enumerate(d["backbone"] + d["head"]): # from, number, module, args
try:
if m == 'node_mode':
m = d[m]
if len(args) > 0:
if args[0] == 'head_channel':
args[0] = int(d[args[0]])
t = m
m = getattr(torch.nn, m[3:]) if 'nn.' in m else globals()[m] # get module
except:
pass
for j, a in enumerate(args):
if isinstance(a, str):
with contextlib.suppress(ValueError):
try:
args[j] = locals()[a] if a in locals() else ast.literal_eval(a)
except:
args[j] = a
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3
):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
if m is C2fAttn:
args[1] = make_divisible(min(args[1], max_channels // 2) * width, 8) # embed channels
args[2] = int(
max(round(min(args[2], max_channels // 2 // 32)) * width, 1) if args[2] > 1 else args[2]
) # num heads
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3):
args.insert(2, n) # number of repeats
n = 1
elif m is AIFI:
args = [ch[f], *args]
elif m is DySample:
c2 = ch[f]
args = [c2, *args]
elif m in (HGStem, HGBlock):
c1, cm, c2 = ch[f], args[0], args[1]
args = [c1, cm, c2, *args[2:]]
if m is HGBlock:
args.insert(4, n) # number of repeats
n = 1
elif m is ResNetLayer:
c2 = args[1] if args[3] else args[1] * 4
elif m is nn.BatchNorm2d:
args = [ch[f]]
elif m is Concat:
c2 = sum(ch[x] for x in f)
elif m in (Detect, WorldDetect, Segment, Pose, OBB, ImagePoolingAttn):
args.append([ch[x] for x in f])
if m is Segment:
args[2] = make_divisible(min(args[2], max_channels) * width, 8)
elif m is RTDETRDecoder: # special case, channels arg must be passed in index 1
args.insert(1, [ch[x] for x in f])
##### backbone
elif isinstance(m, str):
t = m
if len(args) == 2:
m = timm.create_model(m, pretrained=args[0], pretrained_cfg_overlay={'file':args[1]}, features_only=True)
elif len(args) == 1:
m = timm.create_model(m, pretrained=args[0], features_only=True)
c2 = m.feature_info.channels()
elif m in {
transnext_micro, transnext_tiny, transnext_small, transnext_base
}:
m = m(*args)
c2 = m.channel
##### backbone
else:
c2 = ch[f]
if isinstance(c2, list):
is_backbone = True
m_ = m
m_.backbone = True
else:
m_ = nn.Sequential(*(m(*args) for _ in range(n))) if n > 1 else m(*args) # module
t = str(m)[8:-2].replace('__main__.', '') # module type
m.np = sum(x.numel() for x in m_.parameters()) # number params
m_.i, m_.f, m_.type = i + 4 if is_backbone else i, f, t # attach index, 'from' index, type
if verbose:
LOGGER.info(f'{i:>3}{str(f):>20}{n_:>3}{m.np:10.0f} {t:<45}{str(args):<30}') # print
save.extend(x % (i + 4 if is_backbone else i) for x in ([f] if isinstance(f, int) else f) if x != -1) # append to savelist
layers.append(m_)
if i == 0:
ch = []
if isinstance(c2, list):
ch.extend(c2)
for _ in range(5 - len(ch)):
ch.insert(0, 0)
else:
ch.append(c2)
return nn.Sequential(*layers), sorted(save)3)修改def _predict_once(self, x, profile=False, visualize=False, embed=None):
建议直接替换
def _predict_once(self, x, profile=False, visualize=False, embed=None):
"""
Perform a forward pass through the network.
Args:
x (torch.Tensor): The input tensor to the model.
profile (bool): Print the computation time of each layer if True, defaults to False.
visualize (bool): Save the feature maps of the model if True, defaults to False.
embed (list, optional): A list of feature vectors/embeddings to return.
Returns:
(torch.Tensor): The last output of the model.
"""
y, dt, embeddings = [], [], [] # outputs
for m in self.model:
if m.f != -1: # if not from previous layer
x = y[m.f] if isinstance(m.f, int) else [x if j == -1 else y[j] for j in m.f] # from earlier layers
if profile:
self._profile_one_layer(m, x, dt)
if hasattr(m, 'backbone'):
x = m(x)
for _ in range(5 - len(x)):
x.insert(0, None)
for i_idx, i in enumerate(x):
if i_idx in self.save:
y.append(i)
else:
y.append(None)
# for i in x:
# if i is not None:
# print(i.size())
x = x[-1]
else:
x = m(x) # run
y.append(x if m.i in self.save else None) # save output
if visualize:
feature_visualization(x, m.type, m.i, save_dir=visualize)
if embed and m.i in embed:
embeddings.append(nn.functional.adaptive_avg_pool2d(x, (1, 1)).squeeze(-1).squeeze(-1)) # flatten
if m.i == max(embed):
return torch.unbind(torch.cat(embeddings, 1), dim=0)
return x4) class DetectionModel(BaseModel):修改
# Build strides
m = self.model[-1] # Detect()
if isinstance(m, Detect): # includes all Detect subclasses like Segment, Pose, OBB, WorldDetect
s = 640 # 2x min stride
m.inplace = self.inplace
forward = lambda x: self.forward(x)[0] if isinstance(m, (Segment, Pose, OBB)) else self.forward(x)
try:
m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(2, ch, s, s))]) # forward
except RuntimeError as e:
if 'Not implemented on the CPU' in str(e) or 'Input type (torch.FloatTensor) and weight type (torch.cuda.FloatTensor)' in str(e) or 'CUDA tensor' in str(e) or 'is_cuda()' in str(e):
self.model.to(torch.device('cuda'))
m.stride = torch.tensor([s / x.shape[-2] for x in forward(torch.zeros(2, ch, s, s).to(torch.device('cuda')))]) # forward
else:
raise e
self.stride = m.stride
m.bias_init() # only run once
else:
self.stride = torch.Tensor([32]) # default stride for i.e. RTDETR2.4 swattention编译
源码下载:https://github.com/DaiShiResearch/TransNeXt

cd swattention_extension
pip install . 编译成功
2.5 yolov8-transnext.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# 0-P1/2
# 1-P2/4
# 2-P3/8
# 3-P4/16
# 4-P5/32
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, transnext_micro, []] # 4
- [-1, 1, SPPF, [1024, 5]] # 5
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 6
- [[-1, 3], 1, Concat, [1]] # 7 cat backbone P4
- [-1, 3, C2f, [512]] # 8
- [-1, 1, nn.Upsample, [None, 2, 'nearest']] # 9
- [[-1, 2], 1, Concat, [1]] # 10 cat backbone P3
- [-1, 3, C2f, [256]] # 11 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]] # 12
- [[-1, 8], 1, Concat, [1]] # 13 cat head P4
- [-1, 3, C2f, [512]] # 14 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]] # 15
- [[-1, 5], 1, Concat, [1]] # 16 cat head P5
- [-1, 3, C2f, [1024]] # 17 (P5/32-large)
- [[11, 14, 17], 1, Detect, [nc]] # Detect(P3, P4, P5)
