💡💡💡本文独家改进:多膨胀通道精炼(MDCR)模块,解决目标的大小微小以及红外图像中通常具有复杂的背景的问题点,2024年3月最新成果
💡💡💡红外小目标实现暴力涨点,只有几个像素的小目标识别率大幅度提升
改进结构图如下:
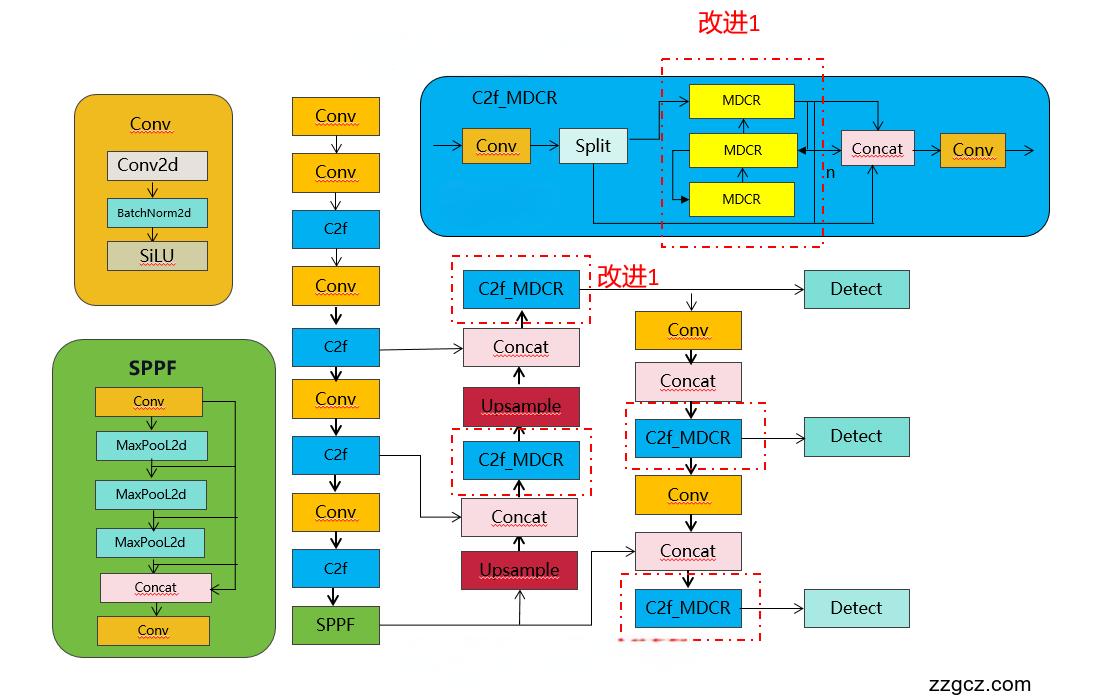
收录
YOLOv8原创自研
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.原理介绍

论文: 2403.10778.pdf (arxiv.org)
摘要: 红外小目标检测是计算机视觉中的一项重要任务,尤其是在红外图像中对微小目标的识别和定位,这些目标通常只有几个像素。然而,由于目标的大小微小以及红外图像中通常具有复杂的背景,这项任务遇到了困难。在本文中,作者提出了HCF-Net,通过多个实用模块显著提高了红外小目标检测的性能。具体来说,它包括并行化 patch-aware 注意力(PPA)模块、维度感知选择性集成(DASI)模块以及多膨胀通道精炼(MDCR)模块。PPA模块采用多分支特征提取策略来捕获不同尺度和 Level 的特征信息。DASI模块实现了自适应通道选择与融合。MDCR模块通过多个深度可分离卷积层捕获不同感受野范围的空间特征。在SIRST红外单帧图像数据集上的大量实验结果表明,所提出的HCF-Net表现良好,超过了其他传统和深度学习模型。

图1为网络结构图。编码器主要包括并行补丁感知注意(PPA)模块和最大池化层,而解码器主要由PPA和卷积转置(CT)层组成。我们将多膨胀通道精炼(MDCR)模块作为中间层以桥接编码器和解码器。在跳跃连接组件中,我们引入了维度感知选择性集成(DASI)模块来增强跨不同网络层的特征融合与传播

图2:描述了一个并行化的patch-aware注意力模块的详细结构。这个模块主要由两个组件组成:多分支融合和注意力机制。多分支融合组件包括patch-aware卷积和拼接卷积。在patch-aware中,'p'参数设置为2和4,分别代表局部分支和全局分支。
 3.图 维度感知选择性集成模块的详细结构
3.图 维度感知选择性集成模块的详细结构
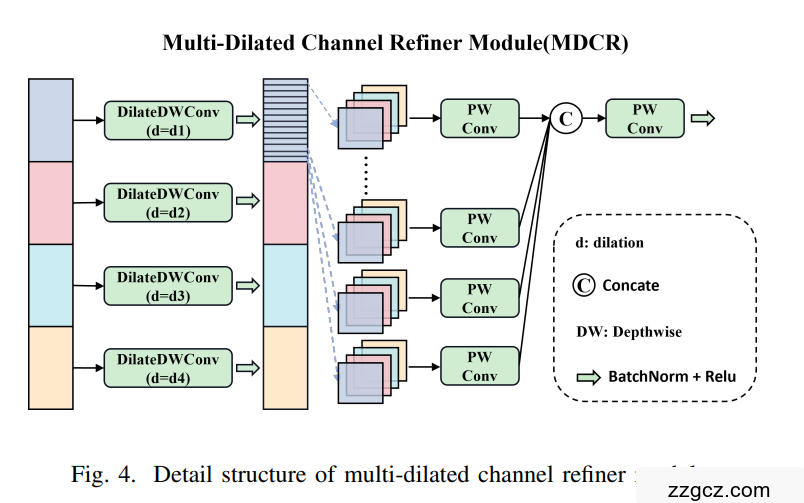
在MDCR中,我们引入了多个深度可分的具有变化的膨胀速率的卷积层以捕获空间在感受野大小范围内的特征,这允许有关对象之间差异的更详细建模,请参阅和背景,增强其区分小对象
2.MDCR将入到YOLOv8
2.1 加入ultralytics/nn/block/HCFNetblocks.py
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
from ultralytics.nn.modules.block import C3,C2f
class conv_block(nn.Module):
def __init__(self,
in_features,
out_features,
kernel_size=(3, 3),
stride=(1, 1),
padding=(1, 1),
dilation=(1, 1),
norm_type='bn',
activation=True,
use_bias=True,
groups=1
):
super().__init__()
self.conv = nn.Conv2d(in_channels=in_features,
out_channels=out_features,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
bias=use_bias,
groups=groups)
self.norm_type = norm_type
self.act = activation
if self.norm_type == 'gn':
self.norm = nn.GroupNorm(32 if out_features >= 32 else out_features, out_features)
if self.norm_type == 'bn':
self.norm = nn.BatchNorm2d(out_features)
if self.act:
# self.relu = nn.GELU()
self.relu = nn.ReLU(inplace=False)
def forward(self, x):
x = self.conv(x)
if self.norm_type is not None:
x = self.norm(x)
if self.act:
x = self.relu(x)
return x
class LocalGlobalAttention(nn.Module):
def __init__(self, output_dim, patch_size):
super().__init__()
self.output_dim = output_dim
self.patch_size = patch_size
self.mlp1 = nn.Linear(patch_size*patch_size, output_dim // 2)
self.norm = nn.LayerNorm(output_dim // 2)
self.mlp2 = nn.Linear(output_dim // 2, output_dim)
self.conv = nn.Conv2d(output_dim, output_dim, kernel_size=1)
self.prompt = torch.nn.parameter.Parameter(torch.randn(output_dim, requires_grad=True))
self.top_down_transform = torch.nn.parameter.Parameter(torch.eye(output_dim), requires_grad=True)
def forward(self, x):
x = x.permute(0, 2, 3, 1)
B, H, W, C = x.shape
P = self.patch_size
# Local branch
local_patches = x.unfold(1, P, P).unfold(2, P, P) # (B, H/P, W/P, P, P, C)
local_patches = local_patches.reshape(B, -1, P*P, C) # (B, H/P*W/P, P*P, C)
local_patches = local_patches.mean(dim=-1) # (B, H/P*W/P, P*P)
local_patches = self.mlp1(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.norm(local_patches) # (B, H/P*W/P, input_dim // 2)
local_patches = self.mlp2(local_patches) # (B, H/P*W/P, output_dim)
local_attention = F.softmax(local_patches, dim=-1) # (B, H/P*W/P, output_dim)
local_out = local_patches * local_attention # (B, H/P*W/P, output_dim)
cos_sim = F.normalize(local_out, dim=-1) @ F.normalize(self.prompt[None, ..., None], dim=1) # B, N, 1
mask = cos_sim.clamp(0, 1)
local_out = local_out * mask
local_out = local_out @ self.top_down_transform
# Restore shapes
local_out = local_out.reshape(B, H // P, W // P, self.output_dim) # (B, H/P, W/P, output_dim)
local_out = local_out.permute(0, 3, 1, 2)
local_out = F.interpolate(local_out, size=(H, W), mode='bilinear', align_corners=False)
output = self.conv(local_out)
return output
class Bag(nn.Module):
def __init__(self):
super(Bag, self).__init__()
def forward(self, p, i, d):
edge_att = torch.sigmoid(d)
return edge_att * p + (1 - edge_att) * i
class ECA(nn.Module):
def __init__(self,in_channel,gamma=2,b=1):
super(ECA, self).__init__()
k=int(abs((math.log(in_channel,2)+b)/gamma))
kernel_size=k if k % 2 else k+1
padding=kernel_size//2
self.pool=nn.AdaptiveAvgPool2d(output_size=1)
self.conv=nn.Sequential(
nn.Conv1d(in_channels=1,out_channels=1,kernel_size=kernel_size,padding=padding,bias=False),
nn.Sigmoid()
)
def forward(self,x):
out=self.pool(x)
out=out.view(x.size(0),1,x.size(1))
out=self.conv(out)
out=out.view(x.size(0),x.size(1),1,1)
return out*x
class SpatialAttentionModule(nn.Module):
def __init__(self):
super(SpatialAttentionModule, self).__init__()
self.conv2d = nn.Conv2d(in_channels=2, out_channels=1, kernel_size=7, stride=1, padding=3)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avgout = torch.mean(x, dim=1, keepdim=True)
maxout, _ = torch.max(x, dim=1, keepdim=True)
out = torch.cat([avgout, maxout], dim=1)
out = self.sigmoid(self.conv2d(out))
return out * x
class PPA(nn.Module):
def __init__(self, in_features, filters) -> None:
super().__init__()
self.skip = conv_block(in_features=in_features,
out_features=filters,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
self.c1 = conv_block(in_features=in_features,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.c2 = conv_block(in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.c3 = conv_block(in_features=filters,
out_features=filters,
kernel_size=(3, 3),
padding=(1, 1),
norm_type='bn',
activation=True)
self.sa = SpatialAttentionModule()
self.cn = ECA(filters)
self.lga2 = LocalGlobalAttention(filters, 2)
self.lga4 = LocalGlobalAttention(filters, 4)
self.bn1 = nn.BatchNorm2d(filters)
self.drop = nn.Dropout2d(0.1)
self.relu = nn.ReLU()
self.gelu = nn.GELU()
def forward(self, x):
x_skip = self.skip(x)
x_lga2 = self.lga2(x_skip)
x_lga4 = self.lga4(x_skip)
x1 = self.c1(x)
x2 = self.c2(x1)
x3 = self.c3(x2)
x = x1 + x2 + x3 + x_skip + x_lga2 + x_lga4
x = self.cn(x)
x = self.sa(x)
x = self.drop(x)
x = self.bn1(x)
x = self.relu(x)
return x
class DASI(nn.Module):
def __init__(self, in_features, out_features) -> None:
super().__init__()
self.bag = Bag()
self.tail_conv = nn.Sequential(
conv_block(in_features=out_features,
out_features=out_features,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
)
self.conv = nn.Sequential(
conv_block(in_features = out_features // 2,
out_features = out_features // 4,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
)
self.bns = nn.BatchNorm2d(out_features)
self.skips = conv_block(in_features=in_features,
out_features=out_features,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
self.skips_2 = conv_block(in_features=in_features * 2,
out_features=out_features,
kernel_size=(1, 1),
padding=(0, 0),
norm_type='bn',
activation=False)
self.skips_3 = nn.Conv2d(in_features//2, out_features,
kernel_size=3, stride=2, dilation=2, padding=2)
# self.skips_3 = nn.Conv2d(in_features//2, out_features,
# kernel_size=3, stride=2, dilation=1, padding=1)
self.relu = nn.ReLU()
self.gelu = nn.GELU()
def forward(self, x):
x_skip = self.skips(x)
x = self.skips(x)
# x = torch.chunk(x, 4, dim=1)
x = self.tail_conv(x)
x += x_skip
x = self.bns(x)
x = self.relu(x)
return x
class C2f_DASI(C2f):
def __init__(self, c1, c2, n=1, k=7, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(DASI(self.c, self.c) for _ in range(n))
class MDCR(nn.Module):
def __init__(self, in_features, out_features, norm_type='bn', activation=True, rate=[1, 2, 4, 8]):
super().__init__()
self.block1 = conv_block(
in_features=in_features//4,
out_features=out_features//4,
padding=rate[0],
dilation=rate[0],
norm_type=norm_type,
activation=activation,
groups=8
)
self.block2 = conv_block(
in_features=in_features//4,
out_features=out_features//4,
padding=rate[1],
dilation=rate[1],
norm_type=norm_type,
activation=activation,
groups=8
)
self.block3 = conv_block(
in_features=in_features//4,
out_features=out_features//4,
padding=rate[2],
dilation=rate[2],
norm_type=norm_type,
activation=activation,
groups=8
)
self.block4 = conv_block(
in_features=in_features//4,
out_features=out_features//4,
padding=rate[3],
dilation=rate[3],
norm_type=norm_type,
activation=activation,
groups=8
)
self.out_s = conv_block(
in_features=4,
out_features=4,
kernel_size=(1, 1),
padding=(0, 0),
norm_type=norm_type,
activation=activation,
)
self.out = conv_block(
in_features=out_features,
out_features=out_features,
kernel_size=(1, 1),
padding=(0, 0),
norm_type=norm_type,
activation=activation,
)
def forward(self, x):
split_tensors = []
x = torch.chunk(x, 4, dim=1)
x1 = self.block1(x[0])
x2 = self.block2(x[1])
x3 = self.block3(x[2])
x4 = self.block4(x[3])
for channel in range(x1.size(1)):
channel_tensors = [tensor[:, channel:channel + 1, :, :] for tensor in [x1, x2, x3, x4]]
concatenated_channel = self.out_s(torch.cat(channel_tensors, dim=1)) # 拼接在 batch_size 维度上
split_tensors.append(concatenated_channel)
x = torch.cat(split_tensors, dim=1)
x = self.out(x)
return x
class C2f_MDCR(C2f):
def __init__(self, c1, c2,n=1, k=7, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(MDCR(self.c, self.c) for _ in range(n))2.2修改task.py
本文改进基于官方最新版本,如新加入C2fAttn等等
下载地址:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
1)首先进行注册
from ultralytics.nn.block.HCFNetblocks import *2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
只需要在你源码基础上加入C2f_MDCR,其他模块为博主其他文章的优化点
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
C2f_MDCR
):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3,C2f_MDCR):
args.insert(2, n) # number of repeats
n = 12.3 yolov8-C2f_MDCR.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f_MDCR, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f_MDCR, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f_MDCR, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f_MDCR, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)