💡💡💡本文原创自研创新改进:提出了一种新的基于尺度变化的注意力网络,用于小尺度目标检测分割。蒙特卡罗注意力(MCAttn)模块使用基于随机抽样的池化操作来生成与尺度无关的注意力图。这使得网络能够捕获不同尺度的相关信息,增强其识别小目标识别分割能力。
💡💡💡新颖度足够,全网独家首发推荐指数五颗星,适用于小目标检测,高效涨点

改进1结构图:
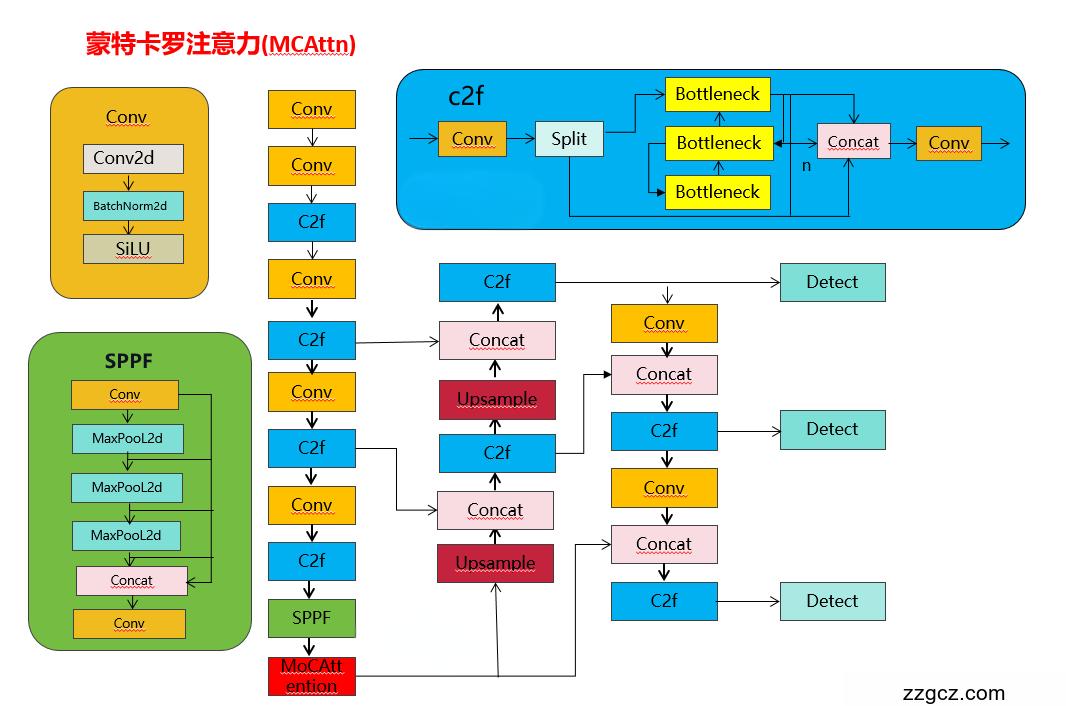
YOLOv8原创自研
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.原理介绍

摘要:早期发现和准确诊断可以预测恶性疾病转化的风险,从而增加有效治疗的概率。轻度综合症
小的感染区域是一个不祥的警告,在疾病的早期诊断中是最重要的。卷积神经网络(cnn)等深度学习算法已被用于分割自然物体或医疗物体,并显示出良好的效果。然而,由于cnn的卷积和池化操作导致的信息丢失和压缩缺陷,对图像中小区域的医学对象进行分析仍然是一个挑战。随着网络的深入,这些损失和缺陷变得越来越明显,特别是对于小型医疗对象。为了解决这些挑战,我们提出了一种新的基于尺度变化的注意力网络(SvANet),用于医学图像中精确的小尺度目标分割。SvANet由蒙特卡罗注意、尺度变化注意和视觉变换组成,融合了跨尺度特征,减轻了压缩伪影,增强了对小型医疗物体的识别。定量实验结果表明,SvANet在分割肾肿瘤、皮肤病变、肝脏肿瘤、息肉、手术切除细胞、视网膜血管和精子方面的平均Dice系数分别达到96.12%、96.11%、89.79%、84.15%、80.25%、73.05%和72.58%,在KiTS23、ISIC 2018、ATLAS、polygen、TissueNet、FIVES和SpermHealth数据集中,这些数据分别占不到1%的图像区域。

图1:scale-variant attention-based network (SvANet)的架构。蒙特卡罗注意力(MCAttn)和基于MCAttn的瓶颈(mc瓶颈)模块,位于左上角的虚线框中,分别学习全局和局部特征。跨尺度引导和尺度变化注意(SvAttn)技术,如图中上虚线框所示,集成了低级和高级特征映射。通过装配张量(AssemFormer)(位于右上方虚线框中)与视觉变压器进行卷积,将局部和全局特征协同关联,结合了卷积神经网络和视觉变压器的优势。
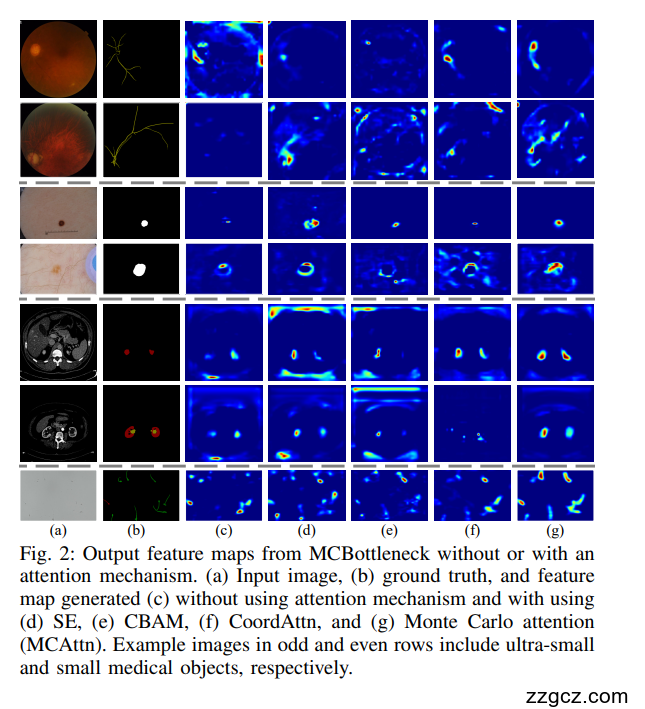
受这种现象的启发,蒙特卡罗注意力(MCAttn)模块使用基于随机抽样的池化操作来生成与尺度无关的注意力图。这使得网络能够捕获不同尺度的相关信息,增强其识别小型医疗对象的能力
在图1中,紫色块表示的MCAttn通过从三个尺度:3×3, 2×2和1×1(池张量)中随机选择1×1注意图来生成注意图。
2.如何加入YOLOv8
3.1新建加入ultralytics/nn/attention/mcattn.py
import numpy as np
from typing import Any, Callable
import torch
from torch import nn, Tensor
from typing import List, Optional
import math
from ultralytics.nn.modules.conv import Conv
def makeDivisible(v: float, divisor: int, min_value: Optional[int] = None) -> int:
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.Py
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
def callMethod(self, ElementName):
return getattr(self, ElementName)
def setMethod(self, ElementName, ElementValue):
return setattr(self, ElementName, ElementValue)
def shuffleTensor(Feature: Tensor, Mode: int=1) -> Tensor:
# shuffle multiple tensors with the same indexs
# all tensors must have the same shape
if isinstance(Feature, Tensor):
Feature = [Feature]
Indexs = None
Output = []
for f in Feature:
# not in-place operation, should update output
B, C, H, W = f.shape
if Mode == 1:
# fully shuffle
f = f.flatten(2)
if Indexs is None:
Indexs = torch.randperm(f.shape[-1], device=f.device)
f = f[:, :, Indexs.to(f.device)]
f = f.reshape(B, C, H, W)
else:
# shuflle along y and then x axis
if Indexs is None:
Indexs = [torch.randperm(H, device=f.device),
torch.randperm(W, device=f.device)]
f = f[:, :, Indexs[0].to(f.device)]
f = f[:, :, :, Indexs[1].to(f.device)]
Output.append(f)
return Output
class AdaptiveAvgPool2d(nn.AdaptiveAvgPool2d):
def __init__(self, output_size: int or tuple=1):
super(AdaptiveAvgPool2d, self).__init__(output_size=output_size)
def profileModule(self, Input: Tensor):
Output = self.forward(Input)
return Output, 0.0, 0.0
class AdaptiveMaxPool2d(nn.AdaptiveMaxPool2d):
def __init__(self, output_size: int or tuple=1):
super(AdaptiveMaxPool2d, self).__init__(output_size=output_size)
def profileModule(self, Input: Tensor):
Output = self.forward(Input)
return Output, 0.0, 0.0
NormLayerTuple = (
nn.BatchNorm1d,
nn.BatchNorm2d,
nn.SyncBatchNorm,
nn.LayerNorm,
nn.InstanceNorm1d,
nn.InstanceNorm2d,
nn.GroupNorm,
nn.BatchNorm3d,
)
def initWeight(Module):
# init conv, norm , and linear layers
## empty module
if Module is None:
return
## conv layer
elif isinstance(Module, (nn.Conv2d, nn.Conv3d, nn.ConvTranspose2d)):
nn.init.kaiming_uniform_(Module.weight, a=math.sqrt(5))
if Module.bias is not None:
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(Module.weight)
if fan_in != 0:
bound = 1 / math.sqrt(fan_in)
nn.init.uniform_(Module.bias, -bound, bound)
## norm layer
elif isinstance(Module, NormLayerTuple):
if Module.weight is not None:
nn.init.ones_(Module.weight)
if Module.bias is not None:
nn.init.zeros_(Module.bias)
## linear layer
elif isinstance(Module, nn.Linear):
nn.init.kaiming_uniform_(Module.weight, a=math.sqrt(5))
if Module.bias is not None:
fan_in, _ = nn.init._calculate_fan_in_and_fan_out(Module.weight)
bound = 1 / math.sqrt(fan_in) if fan_in > 0 else 0
nn.init.uniform_(Module.bias, -bound, bound)
elif isinstance(Module, (nn.Sequential, nn.ModuleList)):
for m in Module:
initWeight(m)
elif list(Module.children()):
for m in Module.children():
initWeight(m)
class BaseConv2d(nn.Module):
def __init__(
self,
in_channels: int,
out_channels: int,
kernel_size: int,
stride: Optional[int] = 1,
padding: Optional[int] = None,
groups: Optional[int] = 1,
bias: Optional[bool] = None,
BNorm: bool = False,
# norm_layer: Optional[Callable[..., nn.Module]]=nn.BatchNorm2d,
ActLayer: Optional[Callable[..., nn.Module]] = None,
dilation: int = 1,
Momentum: Optional[float] = 0.1,
**kwargs: Any
) -> None:
super(BaseConv2d, self).__init__()
if padding is None:
padding = int((kernel_size - 1) // 2 * dilation)
if bias is None:
bias = not BNorm
self.in_channels = in_channels
self.out_channels = out_channels
self.kernel_size = kernel_size
self.stride = stride
self.padding = padding
self.groups = groups
self.bias = bias
self.Conv = nn.Conv2d(in_channels, out_channels,
kernel_size, stride, padding, dilation, groups, bias, **kwargs)
self.Bn = nn.BatchNorm2d(out_channels, eps=0.001, momentum=Momentum) if BNorm else nn.Identity()
if ActLayer is not None:
if isinstance(list(ActLayer().named_modules())[0][1], nn.Sigmoid):
self.Act = ActLayer()
else:
self.Act = ActLayer(inplace=True)
else:
self.Act = ActLayer
self.apply(initWeight)
def forward(self, x: Tensor) -> Tensor:
x = self.Conv(x)
x = self.Bn(x)
if self.Act is not None:
x = self.Act(x)
return x
def profileModule(self, Input: Tensor):
if Input.dim() != 4:
print('Conv2d requires 4-dimensional Input (BxCxHxW). Provided Input has shape: {}'.format(Input.size()))
BatchSize, in_channels, in_h, in_w = Input.size()
assert in_channels == self.in_channels, '{}!={}'.format(in_channels, self.in_channels)
k_h, k_w = pair(self.kernel_size)
stride_h, stride_w = pair(self.stride)
pad_h, pad_w = pair(self.padding)
groups = self.groups
out_h = (in_h - k_h + 2 * pad_h) // stride_h + 1
out_w = (in_w - k_w + 2 * pad_w) // stride_w + 1
# compute MACs
MACs = (k_h * k_w) * (in_channels * self.out_channels) * (out_h * out_w) * 1.0
MACs /= groups
if self.bias:
MACs += self.out_channels * out_h * out_w
# compute parameters
Params = sum([p.numel() for p in self.parameters()])
Output = torch.zeros(size=(BatchSize, self.out_channels, out_h, out_w), dtype=Input.dtype, device=Input.device)
# print(MACs)
return Output, Params, MACs
class MoCAttention(nn.Module):
# Monte carlo attention
def __init__(
self,
InChannels: int,
HidChannels: int=None,
SqueezeFactor: int=4,
PoolRes: list=[1, 2, 3],
Act: Callable[..., nn.Module]=nn.ReLU,
ScaleAct: Callable[..., nn.Module]=nn.Sigmoid,
MoCOrder: bool=True,
**kwargs: Any,
) -> None:
super().__init__()
if HidChannels is None:
HidChannels = max(makeDivisible(InChannels // SqueezeFactor, 8), 32)
AllPoolRes = PoolRes + [1] if 1 not in PoolRes else PoolRes
for k in AllPoolRes:
Pooling = AdaptiveAvgPool2d(k)
setMethod(self, 'Pool%d' % k, Pooling)
self.SELayer = nn.Sequential(
BaseConv2d(InChannels, HidChannels, 1, ActLayer=Act),
BaseConv2d(HidChannels, InChannels, 1, ActLayer=ScaleAct),
)
self.PoolRes = PoolRes
self.MoCOrder = MoCOrder
def monteCarloSample(self, x: Tensor) -> Tensor:
if self.training:
PoolKeep = np.random.choice(self.PoolRes)
x1 = shuffleTensor(x)[0] if self.MoCOrder else x
AttnMap: Tensor = callMethod(self, 'Pool%d' % PoolKeep)(x1)
if AttnMap.shape[-1] > 1:
AttnMap = AttnMap.flatten(2)
AttnMap = AttnMap[:, :, torch.randperm(AttnMap.shape[-1])[0]]
AttnMap = AttnMap[:, :, None, None] # squeeze twice
else:
AttnMap: Tensor = callMethod(self, 'Pool%d' % 1)(x)
return AttnMap
def forward(self, x: Tensor) -> Tensor:
AttnMap = self.monteCarloSample(x)
return x * self.SELayer(AttnMap)
class PSMoCA(nn.Module):
def __init__(self, c1, c2, e=0.5):
super().__init__()
assert (c1 == c2)
self.c = int(c1 * e)
self.cv1 = Conv(c1, 2 * self.c, 1, 1)
self.cv2 = Conv(2 * self.c, c1, 1)
self.attn = MoCAttention(self.c)
self.ffn = nn.Sequential(
Conv(self.c, self.c * 2, 1),
Conv(self.c * 2, self.c, 1, act=False)
)
def forward(self, x):
a, b = self.cv1(x).split((self.c, self.c), dim=1)
b = b + self.attn(b)
b = b + self.ffn(b)
return self.cv2(torch.cat((a, b), 1))3.2 注册ultralytics/nn/tasks.py
1)MoCAttention进行注册
from ultralytics.nn.attention.mcattn import MoCAttention2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
不要直接复制以下代码,只需要将 MoCAttention加入你的工程
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
MoCAttention
):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3):
args.insert(2, n) # number of repeats
n = 12.3 yolov8-MoCAttention.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, MoCAttention, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)