💡💡💡创新点:来自 MIT 等机构的研究者提出了一种非常有潜力的替代方法 KAN。该方法在准确性和可解释性方面表现优于 MLP。而且,它能以非常少的参数量胜过以更大参数量运行的 MLP。
KAN 在边上具有激活函数,而 MLP 在节点上具有激活函数。KAN 似乎比 MLP 的参数效率更高
💡💡💡如何跟YOLOv8结合:KANConv结合C2f从而替代YOLOv8的C2f,结构图如下
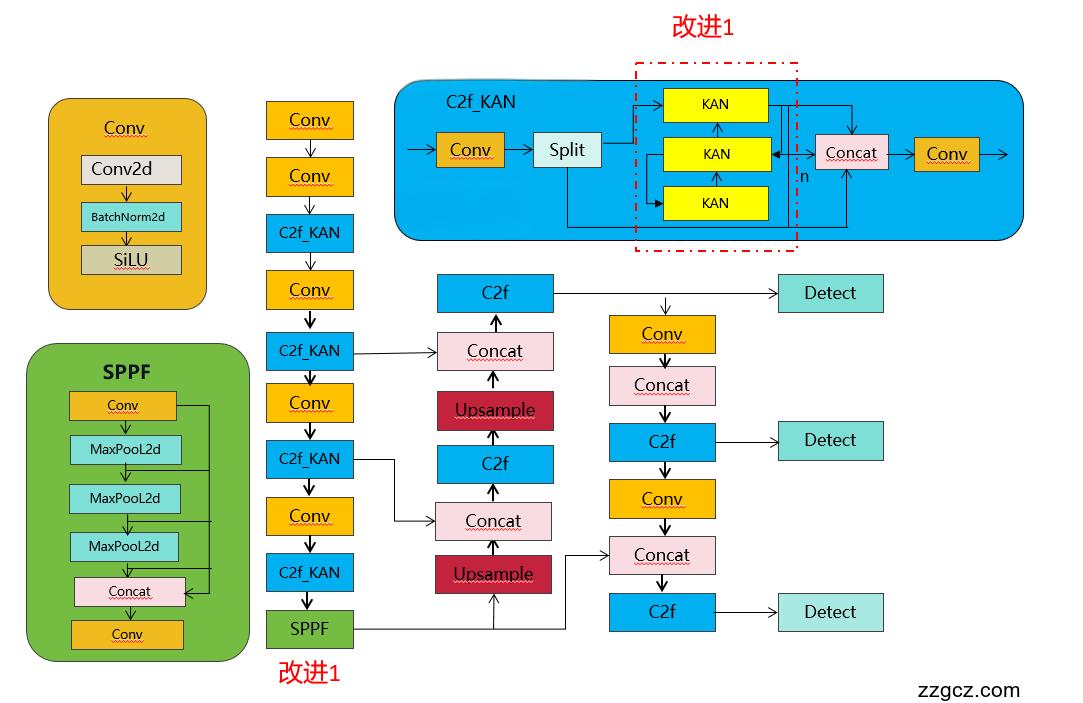
YOLOv8原创自研
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.原理介绍

摘要:受Kolmogorov-Arnold表示定理的启发,我们提出Kolmogorov-Arnold网络(KANs)作为多层感知器(mlp)的有前途的替代品。mlp在节点(“神经元”)上有固定的激活函数,而kan在边缘(“权重”)上有可学习的激活函数。kan根本没有线性权重——每个权重参数都被参数化为样条的单变量函数所取代。我们表明,这个看似简单的改变使得KANs在准确性和可解释性方面优于mlp。就准确性而言,在数据拟合和PDE求解方面,更小的kan可以达到与更大的mlp相当或更好的准确性。从理论上和实证上看,kan比mlp具有更快的神经尺度规律。对于可解释性,KANs可以直观地可视化,并且可以轻松地与人类用户交互。通过数学和物理的两个例子,kan被证明是有用的“合作者”,帮助科学家(重新)发现数学和物理定律。总之,KANs是mlp的有希望的替代品,为进一步改进当今严重依赖mlp的深度学习模型提供了机会。
KAN 在边上具有激活函数,而 MLP 在节点上具有激活函数。KAN 看起来比 MLP 的参数效率更高,但每个 KAN 层比 MLP 层拥有更多的参数。

我们提出的Kolmogorov-Arnold网络是为了纪念两位伟大的已故数学家,Andrey
Kolmogorov和Vladimir Arnold。kan在数学上是合理的、准确的和可解释的。
 2.如何将入到YOLOv8
2.如何将入到YOLOv8
2.1 新建ultralytics/nn/conv/kan_conv.py
import torch
import torch.nn as nn
from ultralytics.nn.modules import (Conv,C3, Bottleneck,C2f)
class KANConvNDLayer(nn.Module):
def __init__(self, conv_class, norm_class, input_dim, output_dim, spline_order, kernel_size,
groups=1, padding=0, stride=1, dilation=1,
ndim: int = 2, grid_size=5, base_activation=nn.GELU, grid_range=[-1, 1], dropout=0.0):
super(KANConvNDLayer, self).__init__()
self.inputdim = input_dim
self.outdim = output_dim
self.spline_order = spline_order
self.kernel_size = kernel_size
self.padding = padding
self.stride = stride
self.dilation = dilation
self.groups = groups
self.ndim = ndim
self.grid_size = grid_size
self.base_activation = base_activation()
self.grid_range = grid_range
self.dropout = None
if dropout > 0:
if ndim == 1:
self.dropout = nn.Dropout1d(p=dropout)
if ndim == 2:
self.dropout = nn.Dropout2d(p=dropout)
if ndim == 3:
self.dropout = nn.Dropout3d(p=dropout)
if groups <= 0:
raise ValueError('groups must be a positive integer')
if input_dim % groups != 0:
raise ValueError('input_dim must be divisible by groups')
if output_dim % groups != 0:
raise ValueError('output_dim must be divisible by groups')
self.base_conv = nn.ModuleList([conv_class(input_dim // groups,
output_dim // groups,
kernel_size,
stride,
padding,
dilation,
groups=1,
bias=False) for _ in range(groups)])
self.spline_conv = nn.ModuleList([conv_class((grid_size + spline_order) * input_dim // groups,
output_dim // groups,
kernel_size,
stride,
padding,
dilation,
groups=1,
bias=False) for _ in range(groups)])
self.layer_norm = nn.ModuleList([norm_class(output_dim // groups) for _ in range(groups)])
self.prelus = nn.ModuleList([nn.PReLU() for _ in range(groups)])
h = (self.grid_range[1] - self.grid_range[0]) / grid_size
self.grid = torch.linspace(
self.grid_range[0] - h * spline_order,
self.grid_range[1] + h * spline_order,
grid_size + 2 * spline_order + 1,
dtype=torch.float32
)
# Initialize weights using Kaiming uniform distribution for better training start
for conv_layer in self.base_conv:
nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')
for conv_layer in self.spline_conv:
nn.init.kaiming_uniform_(conv_layer.weight, nonlinearity='linear')
def forward_kan(self, x, group_index):
# Apply base activation to input and then linear transform with base weights
base_output = self.base_conv[group_index](self.base_activation(x))
x_uns = x.unsqueeze(-1) # Expand dimensions for spline operations.
# Compute the basis for the spline using intervals and input values.
target = x.shape[1:] + self.grid.shape
grid = self.grid.view(*list([1 for _ in range(self.ndim + 1)] + [-1, ])).expand(target).contiguous().to(x.device)
bases = ((x_uns >= grid[..., :-1]) & (x_uns < grid[..., 1:])).to(x.dtype)
# Compute the spline basis over multiple orders.
for k in range(1, self.spline_order + 1):
left_intervals = grid[..., :-(k + 1)]
right_intervals = grid[..., k:-1]
delta = torch.where(right_intervals == left_intervals, torch.ones_like(right_intervals),
right_intervals - left_intervals)
bases = ((x_uns - left_intervals) / delta * bases[..., :-1]) + \
((grid[..., k + 1:] - x_uns) / (grid[..., k + 1:] - grid[..., 1:(-k)]) * bases[..., 1:])
bases = bases.contiguous()
bases = bases.moveaxis(-1, 2).flatten(1, 2)
spline_output = self.spline_conv[group_index](bases)
x = self.prelus[group_index](self.layer_norm[group_index](base_output + spline_output))
if self.dropout is not None:
x = self.dropout(x)
return x
def forward(self, x):
split_x = torch.split(x, self.inputdim // self.groups, dim=1)
output = []
for group_ind, _x in enumerate(split_x):
y = self.forward_kan(_x, group_ind)
output.append(y.clone())
y = torch.cat(output, dim=1)
return y
class KANConv2DLayer(KANConvNDLayer):
def __init__(self, input_dim, output_dim, kernel_size, spline_order=3, groups=1, padding=0, stride=1, dilation=1,
grid_size=5, base_activation=nn.GELU, grid_range=[-1, 1], dropout=0.0):
super(KANConv2DLayer, self).__init__(nn.Conv2d, nn.InstanceNorm2d,
input_dim, output_dim,
spline_order, kernel_size,
groups=groups, padding=padding, stride=stride, dilation=dilation,
ndim=2,
grid_size=grid_size, base_activation=base_activation,
grid_range=grid_range, dropout=dropout)
class Bottleneck_KAN(Bottleneck):
def __init__(self, c1, c2, kan_mothed, shortcut=True, g=1, k=(3, 3), e=0.5):
super().__init__(c1, c2, shortcut, g, k, e)
c_ = int(c2 * e) # hidden channels
self.cv1 = KANConv2DLayer(c1, c_, k[0], padding=k[0] // 2)
self.cv2 = KANConv2DLayer(c_, c2, k[1], padding=k[1] // 2)
class C2f_KAN(C2f):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(Bottleneck_KAN(self.c, self.c, shortcut, g, k=(3, 3), e=1.0) for _ in range(n))2.2 修改task.py
1)首先进行注册
from ultralytics.nn.conv.kan_conv import C2f_KAN2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
不要直接复制以下代码,只需要将 C2f_KAN加入你的工程
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
C2f_KAN
):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3,C2f_KAN):
args.insert(2, n) # number of repeats
n = 1 
2.3 yolov8_C2f_KAN.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f_KAN, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f_KAN, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f_KAN, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f_KAN, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)