💡💡💡解决什么问题:许多网络不能很好地去除图像采集或传输过程中产生的真实噪声(即空间变异噪声),这严重阻碍了它们在实际图像去噪任务中的应用。
💡💡💡创新点:提出了一种新的双分支残差注意网络用于图像去噪,它具有广泛的模型架构和注意引导特征学习的优点。该模型包含两个不同的并行分支,可以捕获互补特征,增强模型的学习能力。我们分别设计了一种新的残差注意力(RAB)和一种新的混合型扩张型残差注意力(HDRAB)。
💡💡💡如何跟YOLOv8结合:RAB和HDRAB引入到backbone
💡💡💡本人在低光照、红外小目标数据集涨点惊喜
改进1结构图如下:
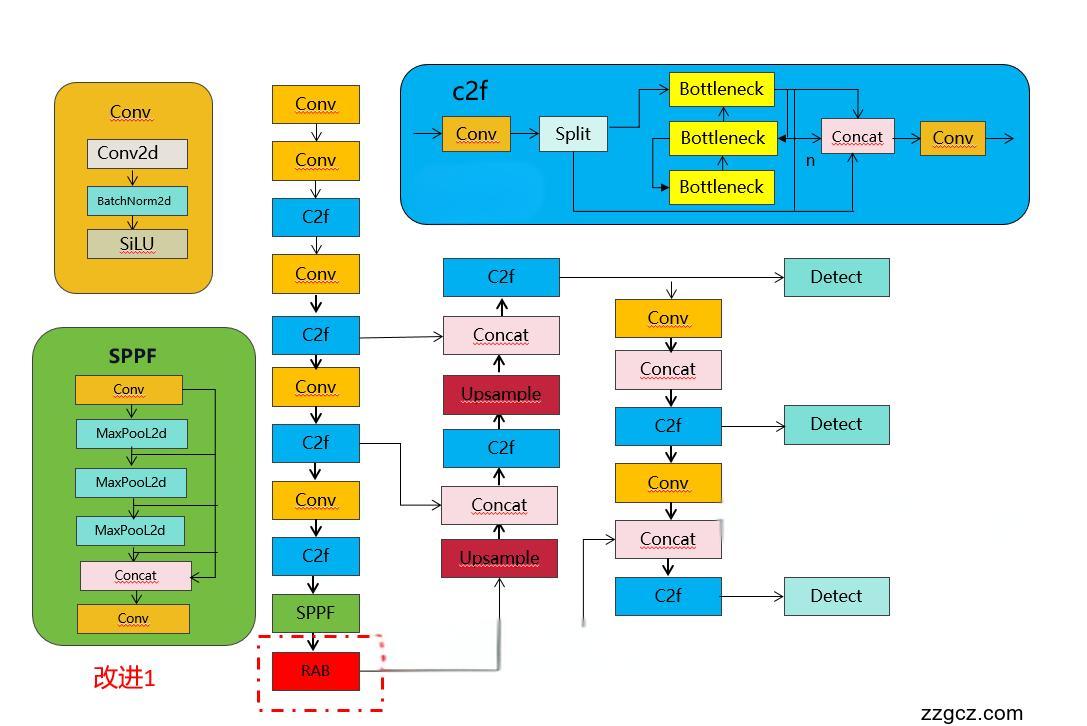
改进2结构图如下:
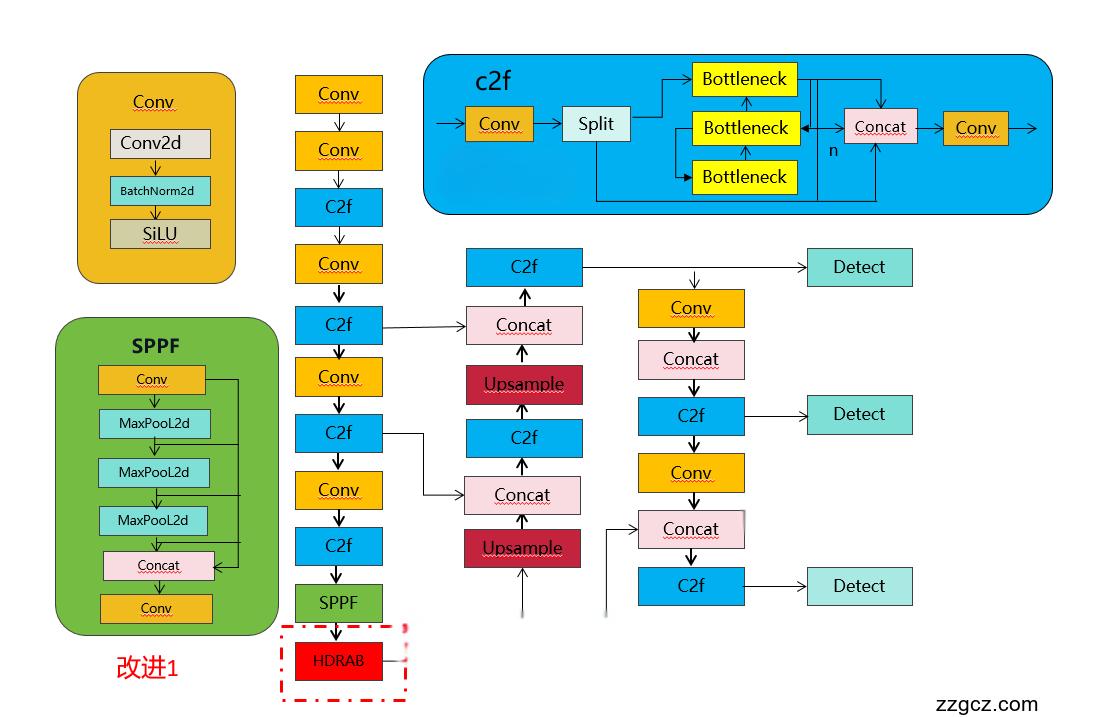
收录
YOLOv8原创自研
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.原理介绍

论文: https://arxiv.org/pdf/2305.04269.pdf
摘要: 在图像去噪中,深度卷积神经网络(cnn)在去除空间不变性噪声方面具有良好的性能。然而,这些网络中的许多不能很好地去除图像采集或传输过程中产生的真实噪声(即空间变异噪声),这严重阻碍了它们在实际图像去噪任务中的应用。许多研究人员发现,与其不断增加网络深度,不如扩大网络宽度,这也是提高模型性能的有效方法。并验证了特征滤波能提高模型的学习能力。因此,在本文中,我们提出了一种新的双分支残差注意网络(DRANet)用于图像去噪,它具有广泛的模型架构和注意引导特征学习的优点。该模型包含两个不同的并行分支,可以捕获互补特征,增强模型的学习能力。我们分别设计了一种新的残差注意力(RAB)和一种新的混合型扩张型残差注意力(HDRAB)。RAB和HDRAB可以通过不同卷积层之间的多次跳过连接捕获丰富的局部特征,而剩余注意模块则丢弃不重要的特征。同时,各分支间的长跳接和两个并行分支间的全局特征融合也可以捕获全局特征。此外,提出的DRANet使用下采样操作和扩张卷积来增加接受野的大小,这可以使DRANet捕获更多的图像上下文信息。大量的实验表明,与其他最先进的去噪方法相比,我们的DRANet在合成和现实世界的去噪方面都能产生具有竞争力的去噪性能。

设计的残差注意块如图2所示。RAB由残差块和空间注意模块(SAM)组成[44]。残差块包括多个标准卷积(Conv)和整流线性单元(ReLU)[54]。丰富的局部特征可以通过卷积层之间的多个跳跃连接来提取,其中图2中的符号“⊕”表示元素明智的加法。由于卷积层只能提取局部信息而不能利用非局部信息,可能导致去噪性能下降,因此采用注意机制捕获和学习全局上下文信息。与现有的残差注意块[48,49]相比,我们的RAB具有更多的跳过连接,可以提取和融合不同卷积层之间的特征,进一步提高去噪性能。
SAM模块用于学习卷积特征之间的空间间关系,其中符号⊗表示元素积。SAM包括GMP (Global Max Pooling)、GAP (Global Average Pooling)、Conv、ReLU和Sigmoid[55]。在我们的RAB中,我们使用GAP和GMP来表示整个图像的统计量,从而使具有更多有用信息的特征被集中,而没有信息的特征被过滤。需要注意的是,通过残差学习,可以使用非常深的网络来提高去噪性能,但也会大大增加网络的复杂度。为了平衡网络复杂度和去噪性能,我们的模型中使用了5种RABs。

我们为模型的下分支设计了混合扩张残差注意块(HDRAB),如图3所示。HDRAB由扩展残余块和通道注意模块(channel attention module, CAM)混合组成[43]。混合扩展残差块包含多个混合扩展卷积(图3中的s- dconv)[36]和ReLU, ReLU可以通过扩展卷积层之间的多个跳跃连接捕获局部特征,其中“s”表示扩展速率,其值范围为1到4,符号“⊕”表示元素加法。扩张卷积可以扩大感受野的大小以捕获更多的图像信息,混合扩张卷积[38]用于消除可能出现的网格现象。据我们所知,没有类似我们HDRAB的块结构。
CAM模块由GAP、Conv、ReLU和Sigmoid组成。CAM用于利用卷积特征之间的通道间关系,图3中的符号“⊗”表示元素积。为了在网络的复杂性和性能之间取得适当的平衡,我们为下层子网配备了5个hdrb。

2.如何加入到YOLOv8
2.1 加入ultralytics/nn/block/DRANet.py
import torch
import torch.nn as nn
import torch.nn.functional as F
class Up(nn.Module):
def __init__(self, nc, bias):
super(Up, self).__init__()
self.up = nn.ConvTranspose2d(in_channels=nc, out_channels=nc, kernel_size=2, stride=2, bias=bias)
def forward(self, x1, x):
x2 = self.up(x1)
diffY = x.size()[2] - x2.size()[2]
diffX = x.size()[3] - x2.size()[3]
x3 = F.pad(x2, [diffX // 2, diffX - diffX // 2, diffY // 2, diffY - diffY // 2])
return x3
## Spatial Attention
class Basic(nn.Module):
def __init__(self, in_planes, out_planes, kernel_size, padding=0, bias=False):
super(Basic, self).__init__()
self.out_channels = out_planes
groups = 1
self.conv = nn.Conv2d(in_planes, out_planes, kernel_size=kernel_size, padding=padding, groups=groups, bias=bias)
self.relu = nn.ReLU()
def forward(self, x):
x = self.conv(x)
x = self.relu(x)
return x
class ChannelPool(nn.Module):
def __init__(self):
super(ChannelPool, self).__init__()
def forward(self, x):
return torch.cat((torch.max(x, 1)[0].unsqueeze(1), torch.mean(x, 1).unsqueeze(1)), dim=1)
class SAB(nn.Module):
def __init__(self):
super(SAB, self).__init__()
kernel_size = 5
self.compress = ChannelPool()
self.spatial = Basic(2, 1, kernel_size, padding=(kernel_size - 1) // 2, bias=False)
def forward(self, x):
x_compress = self.compress(x)
x_out = self.spatial(x_compress)
scale = torch.sigmoid(x_out)
return x * scale
## Channel Attention Layer
class CAB(nn.Module):
def __init__(self, nc, reduction=8, bias=False):
super(CAB, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv_du = nn.Sequential(
nn.Conv2d(nc, nc // reduction, kernel_size=1, padding=0, bias=bias),
nn.ReLU(inplace=True),
nn.Conv2d(nc // reduction, nc, kernel_size=1, padding=0, bias=bias),
nn.Sigmoid()
)
def forward(self, x):
y = self.avg_pool(x)
y = self.conv_du(y)
return x * y
class RAB(nn.Module):
def __init__(self, in_channels=64, out_channels=64, bias=True):
super(RAB, self).__init__()
kernel_size = 3
stride = 1
padding = 1
layers = []
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias))
layers.append(nn.ReLU(inplace=True))
layers.append(nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, stride=stride, padding=padding, bias=bias))
self.res = nn.Sequential(*layers)
self.sab = SAB()
def forward(self, x):
x1 = x + self.res(x)
x2 = x1 + self.res(x1)
x3 = x2 + self.res(x2)
x3_1 = x1 + x3
x4 = x3_1 + self.res(x3_1)
x4_1 = x + x4
x5 = self.sab(x4_1)
x5_1 = x + x5
return x5_1
class HDRAB(nn.Module):
def __init__(self, in_channels=64, out_channels=64, bias=True):
super(HDRAB, self).__init__()
kernel_size = 3
reduction = 8
self.cab = CAB(in_channels, reduction, bias)
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=1, dilation=1, bias=bias)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=2, dilation=2, bias=bias)
self.conv3 = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=3, dilation=3, bias=bias)
self.relu3 = nn.ReLU(inplace=True)
self.conv4 = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=4, dilation=4, bias=bias)
self.conv3_1 = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=3, dilation=3, bias=bias)
self.relu3_1 = nn.ReLU(inplace=True)
self.conv2_1 = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=2, dilation=2, bias=bias)
self.conv1_1 = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=1, dilation=1, bias=bias)
self.relu1_1 = nn.ReLU(inplace=True)
self.conv_tail = nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, padding=1, dilation=1, bias=bias)
def forward(self, y):
y1 = self.conv1(y)
y1_1 = self.relu1(y1)
y2 = self.conv2(y1_1)
y2_1 = y2 + y
y3 = self.conv3(y2_1)
y3_1 = self.relu3(y3)
y4 = self.conv4(y3_1)
y4_1 = y4 + y2_1
y5 = self.conv3_1(y4_1)
y5_1 = self.relu3_1(y5)
y6 = self.conv2_1(y5_1+y3)
y6_1 = y6 + y4_1
y7 = self.conv1_1(y6_1+y2_1)
y7_1 = self.relu1_1(y7)
y8 = self.conv_tail(y7_1+y1)
y8_1 = y8 + y6_1
y9 = self.cab(y8_1)
y9_1 = y + y9
return y9_1
2.2修改task.py
本文改进基于官方最新版本,如新加入C2fAttn等等
下载地址:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite
1)首先进行注册
from ultralytics.nn.block.DRANet import RAB,HDRAB2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
只需要在你源码基础上加入 RAB,HDRAB,其他模块为博主其他文章的优化点
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
RAB,HDRAB
):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3):
args.insert(2, n) # number of repeats
n = 1
2.3 yolov8-RAB.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, RAB, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19(P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)
2.4 yolov8-HDRAB.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, HDRAB, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19(P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)