💡💡💡本文独家改进:CVPR2024 清华提出RepViT:轻量级新主干!从ViT角度重新审视移动CNN,RepViTBlock和C2f进行结合实现二次创新
改进结构图如下:
收录
YOLOv8原创自研
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1. RepViT介绍

论文:https://arxiv.org/pdf/2307.09283.pdf
重点探讨了在资源有限的移动设备上,通过重新审视轻量级卷积神经网络的设计,并整合轻量级 ViTs 的有效架构选择,来提升轻量级 CNNs 的性能。
本文贡献:
- 文中提到,轻量级 ViTs 通常比轻量级 CNNs 在视觉任务上表现得更好,这主要归功于它们的多头自注意力模块(
MSHA)可以让模型学习全局表示。然而,轻量级 ViTs 和轻量级 CNNs 之间的架构差异尚未得到充分研究。 - 在这项研究中,作者们通过整合轻量级 ViTs 的有效架构选择,逐步提升了标准轻量级 CNN(特别是
MobileNetV3的移动友好性。这便衍生出一个新的纯轻量级 CNN 家族的诞生,即RepViT。值得注意的是,尽管 RepViT 具有 MetaFormer 结构,但它完全由卷积组成。 - 实验结果表明,
RepViT超越了现有的最先进的轻量级 ViTs,并在各种视觉任务上显示出优于现有最先进轻量级ViTs的性能和效率,包括 ImageNet 分类、COCO-2017 上的目标检测和实例分割,以及 ADE20k 上的语义分割。特别地,在ImageNet上,RepViT在iPhone 12上达到了近乎 1ms 的延迟和超过 80% 的Top-1 准确率,这是轻量级模型的首次突破。

通过集成轻量级 ViT 的高效架构选择,逐步增强标准轻量级 CNN(特别是 MobileNetV3)的移动友好性。 最终产生了一个新的纯轻量级 CNN 系列,即 RepViT。
RepViT 通过逐层微观设计来调整轻量级 CNN,这包括选择合适的卷积核大小和优化挤压-激励(Squeeze-and-excitation,简称SE)层的位置。这两种方法都能显著改善模型性能。

浅层网络使用卷积提取器


更深的下采样层,作者们首先使用一个 1x1 卷积来调整通道维度,然后将两个 1x1 卷积的输入和输出通过残差连接,形成一个前馈网络。此外,他们还在前面增加了一个 RepViT 块以进一步加深下采样层,这一步提高了 top-1 准确率到 75.4%,同时延迟为 0.96ms。

最终,通过整合上述改进策略,我们便得到了模型RepViT的整体架构,该模型有多个变种,例如RepViT-M1/M2/M3。同样地,不同的变种主要通过每个阶段的通道数和块数来区分。

2.基于Yolov8的RepViTBlock实现
2.1 加入ultralytics/nn/backbone/RepViTBlock.py
import torch.nn as nn
import torch
from timm.models.layers import SqueezeExcite
from ultralytics.nn.modules.block import C3,C2f
def replace_batchnorm(net):
for child_name, child in net.named_children():
if hasattr(child, 'fuse_self'):
fused = child.fuse_self()
setattr(net, child_name, fused)
replace_batchnorm(fused)
elif isinstance(child, torch.nn.BatchNorm2d):
setattr(net, child_name, torch.nn.Identity())
else:
replace_batchnorm(child)
def _make_divisible(v, divisor, min_value=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
:param v:
:param divisor:
:param min_value:
:return:
"""
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_v < 0.9 * v:
new_v += divisor
return new_v
class Conv2d_BN(torch.nn.Sequential):
def __init__(self, a, b, ks=1, stride=1, pad=0, dilation=1,
groups=1, bn_weight_init=1, resolution=-10000):
super().__init__()
self.add_module('c', torch.nn.Conv2d(
a, b, ks, stride, pad, dilation, groups, bias=False))
self.add_module('bn', torch.nn.BatchNorm2d(b))
torch.nn.init.constant_(self.bn.weight, bn_weight_init)
torch.nn.init.constant_(self.bn.bias, 0)
@torch.no_grad()
def fuse_self(self):
c, bn = self._modules.values()
w = bn.weight / (bn.running_var + bn.eps) ** 0.5
w = c.weight * w[:, None, None, None]
b = bn.bias - bn.running_mean * bn.weight / \
(bn.running_var + bn.eps) ** 0.5
m = torch.nn.Conv2d(w.size(1) * self.c.groups, w.size(
0), w.shape[2:], stride=self.c.stride, padding=self.c.padding, dilation=self.c.dilation,
groups=self.c.groups,
device=c.weight.device)
m.weight.data.copy_(w)
m.bias.data.copy_(b)
return m
class Residual(torch.nn.Module):
def __init__(self, m, drop=0.):
super().__init__()
self.m = m
self.drop = drop
def forward(self, x):
if self.training and self.drop > 0:
return x + self.m(x) * torch.rand(x.size(0), 1, 1, 1,
device=x.device).ge_(self.drop).div(1 - self.drop).detach()
else:
return x + self.m(x)
@torch.no_grad()
def fuse_self(self):
if isinstance(self.m, Conv2d_BN):
m = self.m.fuse_self()
assert (m.groups == m.in_channels)
identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)
identity = torch.nn.functional.pad(identity, [1, 1, 1, 1])
m.weight += identity.to(m.weight.device)
return m
elif isinstance(self.m, torch.nn.Conv2d):
m = self.m
assert (m.groups != m.in_channels)
identity = torch.ones(m.weight.shape[0], m.weight.shape[1], 1, 1)
identity = torch.nn.functional.pad(identity, [1, 1, 1, 1])
m.weight += identity.to(m.weight.device)
return m
else:
return self
class RepVGGDW(torch.nn.Module):
def __init__(self, ed) -> None:
super().__init__()
self.conv = Conv2d_BN(ed, ed, 3, 1, 1, groups=ed)
self.conv1 = torch.nn.Conv2d(ed, ed, 1, 1, 0, groups=ed)
self.dim = ed
self.bn = torch.nn.BatchNorm2d(ed)
def forward(self, x):
return self.bn((self.conv(x) + self.conv1(x)) + x)
@torch.no_grad()
def fuse_self(self):
conv = self.conv.fuse_self()
conv1 = self.conv1
conv_w = conv.weight
conv_b = conv.bias
conv1_w = conv1.weight
conv1_b = conv1.bias
conv1_w = torch.nn.functional.pad(conv1_w, [1, 1, 1, 1])
identity = torch.nn.functional.pad(torch.ones(conv1_w.shape[0], conv1_w.shape[1], 1, 1, device=conv1_w.device),
[1, 1, 1, 1])
final_conv_w = conv_w + conv1_w + identity
final_conv_b = conv_b + conv1_b
conv.weight.data.copy_(final_conv_w)
conv.bias.data.copy_(final_conv_b)
bn = self.bn
w = bn.weight / (bn.running_var + bn.eps) ** 0.5
w = conv.weight * w[:, None, None, None]
b = bn.bias + (conv.bias - bn.running_mean) * bn.weight / \
(bn.running_var + bn.eps) ** 0.5
conv.weight.data.copy_(w)
conv.bias.data.copy_(b)
return conv
class RepViTBlock(nn.Module):
def __init__(self, inp, oup, use_se=True):
super(RepViTBlock, self).__init__()
self.identity = inp == oup
hidden_dim = 2 * inp
self.token_mixer = nn.Sequential(
RepVGGDW(inp),
SqueezeExcite(inp, 0.25) if use_se else nn.Identity(),
)
self.channel_mixer = Residual(nn.Sequential(
# pw
Conv2d_BN(inp, hidden_dim, 1, 1, 0),
nn.GELU(),
# pw-linear
Conv2d_BN(hidden_dim, oup, 1, 1, 0, bn_weight_init=0),
))
def forward(self, x):
return self.channel_mixer(self.token_mixer(x))
class C3_RepViTBlock(C3):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
c_ = int(c2 * e) # hidden channels
self.m = nn.Sequential(*(RepViTBlock(c_, c_, False) for _ in range(n)))
class C2f_RepViTBlock(C2f):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(RepViTBlock(self.c, self.c, False) for _ in range(n))2.2修改task.py
1)首先进行注册
from ultralytics.nn.backbone.RepViTBlock import *2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
只需要在你源码基础上加入C2f_RepViTBlock,其他模块为博主其他文章的优化点
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
C2f_RepViTBlock
):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3,C2f_RepViTBlock):
args.insert(2, n) # number of repeats
n = 12.3 yolov8-C2f_RepViTBlock.yaml
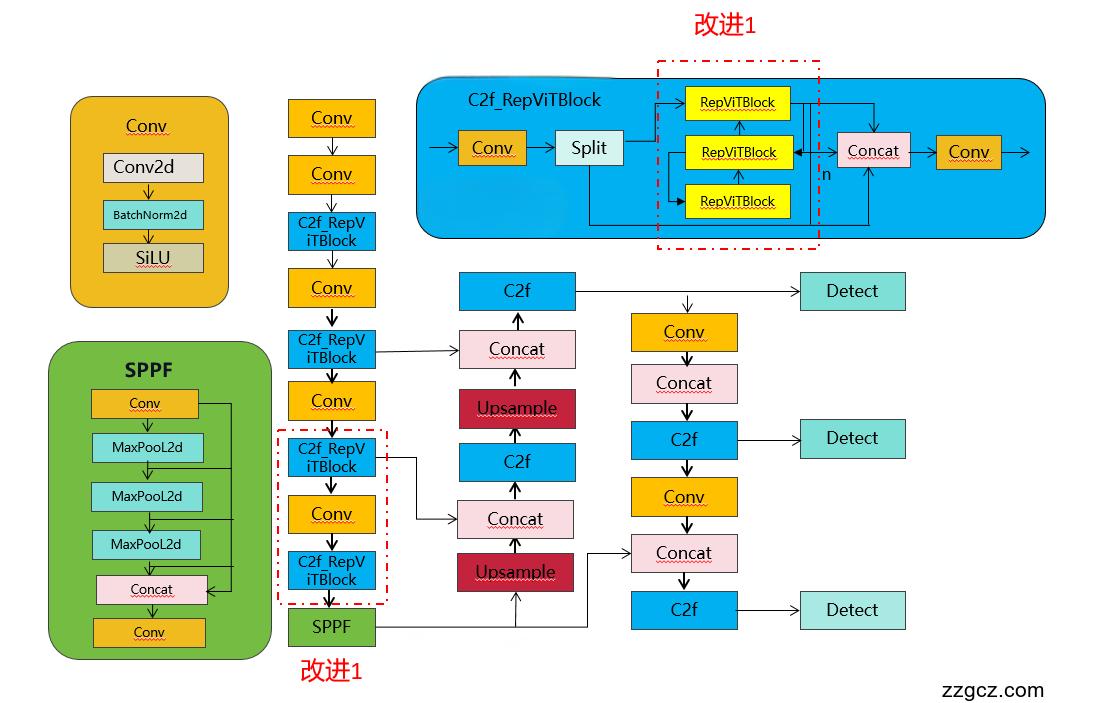
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f_RepViTBlock, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f_RepViTBlock, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f_RepViTBlock, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f_RepViTBlock, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)