💡💡💡创新点:轻量化之王MobileNetV4 开源 | Top-1 精度 87%,手机推理速度 3.8ms,原地起飞!
最主要创新:引入了通用倒瓶颈(UIB)搜索块,这是一个统一且灵活的结构,它融合了倒瓶颈(IB)、ConvNext、前馈网络(FFN)以及一种新颖的额外深度可分(ExtraDW)变体技术。
💡💡💡如何跟YOLOv8结合:替代YOLOv8的C2f
收录
YOLOv8原创自研
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.原理介绍

论文: https://arxiv.org/pdf/2404.10518
摘要:我们介绍了最新一代的mobilenet,被称为MobileNetV4 (MNv4),具有普遍有效的移动设备架构设计。在其核心,我们引入了通用倒瓶颈(UIB)搜索块,这是一个统一而灵活的结构,它融合了倒瓶颈(IB), ConvNext,前馈网络(FFN)和一个新的Extra depth(引渡)变体。除了UIB之外,我们还推出了Mobile MQA,这是一款专为移动加速器量身定制的注意力块,可显著提高39%的速度。介绍了一种优化的神经结构搜索(NAS)配方,提高了MNv4的搜索效率。UIB, Mobile MQA和精致的NAS配方的集成产生了一套新的MNv4模型,这些模型在移动cpu, dsp, gpu以及专用加速器(如Apple Neural Engine和Google Pixel EdgeTPU)上大多是最优的,这是任何其他模型测试中没有发现的特征。最后,为了进一步提高精度,我们介绍了一种新的蒸馏技术。通过这种技术的增强,我们的MNv4-Hybrid-Large模型提供了87%的ImageNet-1K精度,Pixel 8 EdgeTPU运行时间仅为3.8ms。

2. mobilenetv4加入YOLOv8
2.1 新建ultralytics/nn/backbone/mobilenetv4block.py
from typing import Any, Callable, Dict, List, Mapping, Optional, Tuple, Union
import torch
import torch.nn as nn
from ultralytics.nn.modules import (Conv,C3, Bottleneck,C2f)
def make_divisible(
value: float,
divisor: int,
min_value: Optional[float] = None,
round_down_protect: bool = True,
) -> int:
"""
This function is copied from here
"https://github.com/tensorflow/models/blob/master/official/vision/modeling/layers/nn_layers.py"
This is to ensure that all layers have channels that are divisible by 8.
Args:
value: A `float` of original value.
divisor: An `int` of the divisor that need to be checked upon.
min_value: A `float` of minimum value threshold.
round_down_protect: A `bool` indicating whether round down more than 10%
will be allowed.
Returns:
The adjusted value in `int` that is divisible against divisor.
"""
if min_value is None:
min_value = divisor
new_value = max(min_value, int(value + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if round_down_protect and new_value < 0.9 * value:
new_value += divisor
return int(new_value)
def conv_2d(inp, oup, kernel_size=3, stride=1, groups=1, bias=False, norm=True, act=True):
conv = nn.Sequential()
padding = (kernel_size - 1) // 2
conv.add_module('conv', nn.Conv2d(inp, oup, kernel_size, stride, padding, bias=bias, groups=groups))
if norm:
conv.add_module('BatchNorm2d', nn.BatchNorm2d(oup))
if act:
conv.add_module('Activation', nn.ReLU6())
return conv
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio, act=False):
super(InvertedResidual, self).__init__()
self.stride = stride
assert stride in [1, 2]
hidden_dim = int(round(inp * expand_ratio))
self.block = nn.Sequential()
if expand_ratio != 1:
self.block.add_module('exp_1x1', conv_2d(inp, hidden_dim, kernel_size=1, stride=1))
self.block.add_module('conv_3x3', conv_2d(hidden_dim, hidden_dim, kernel_size=3, stride=stride, groups=hidden_dim))
self.block.add_module('red_1x1', conv_2d(hidden_dim, oup, kernel_size=1, stride=1, act=act))
self.use_res_connect = self.stride == 1 and inp == oup
def forward(self, x):
if self.use_res_connect:
return x + self.block(x)
else:
return self.block(x)
class UniversalInvertedBottleneckBlock(nn.Module):
def __init__(self,
inp,
oup,
start_dw_kernel_size=0,
middle_dw_kernel_size=3,
middle_dw_downsample=True,
stride=1,
expand_ratio=2
):
super().__init__()
# Starting depthwise conv.
self.start_dw_kernel_size = start_dw_kernel_size
if self.start_dw_kernel_size:
stride_ = stride if not middle_dw_downsample else 1
self._start_dw_ = conv_2d(inp, inp, kernel_size=start_dw_kernel_size, stride=stride_, groups=inp, act=False)
# Expansion with 1x1 convs.
expand_filters = make_divisible(inp * expand_ratio, 8)
self._expand_conv = conv_2d(inp, expand_filters, kernel_size=1)
# Middle depthwise conv.
self.middle_dw_kernel_size = middle_dw_kernel_size
if self.middle_dw_kernel_size:
stride_ = stride if middle_dw_downsample else 1
self._middle_dw = conv_2d(expand_filters, expand_filters, kernel_size=middle_dw_kernel_size, stride=stride_, groups=expand_filters)
# Projection with 1x1 convs.
self._proj_conv = conv_2d(expand_filters, oup, kernel_size=1, stride=1, act=False)
# Ending depthwise conv.
# this not used
# _end_dw_kernel_size = 0
# self._end_dw = conv_2d(oup, oup, kernel_size=_end_dw_kernel_size, stride=stride, groups=inp, act=False)
def forward(self, x):
if self.start_dw_kernel_size:
x = self._start_dw_(x)
# print("_start_dw_", x.shape)
x = self._expand_conv(x)
# print("_expand_conv", x.shape)
if self.middle_dw_kernel_size:
x = self._middle_dw(x)
# print("_middle_dw", x.shape)
x = self._proj_conv(x)
# print("_proj_conv", x.shape)
return x
class C2f_UIB(C2f):
def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5):
super().__init__(c1, c2, n, shortcut, g, e)
self.m = nn.ModuleList(UniversalInvertedBottleneckBlock(self.c, self.c) for _ in range(n))2.2 修改task.py
1)首先进行注册
from ultralytics.nn.backbone.mobilenetv4block import C2f_UIB2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
C2f_UIB
):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3,C2f_UIB):
args.insert(2, n) # number of repeats
n = 1
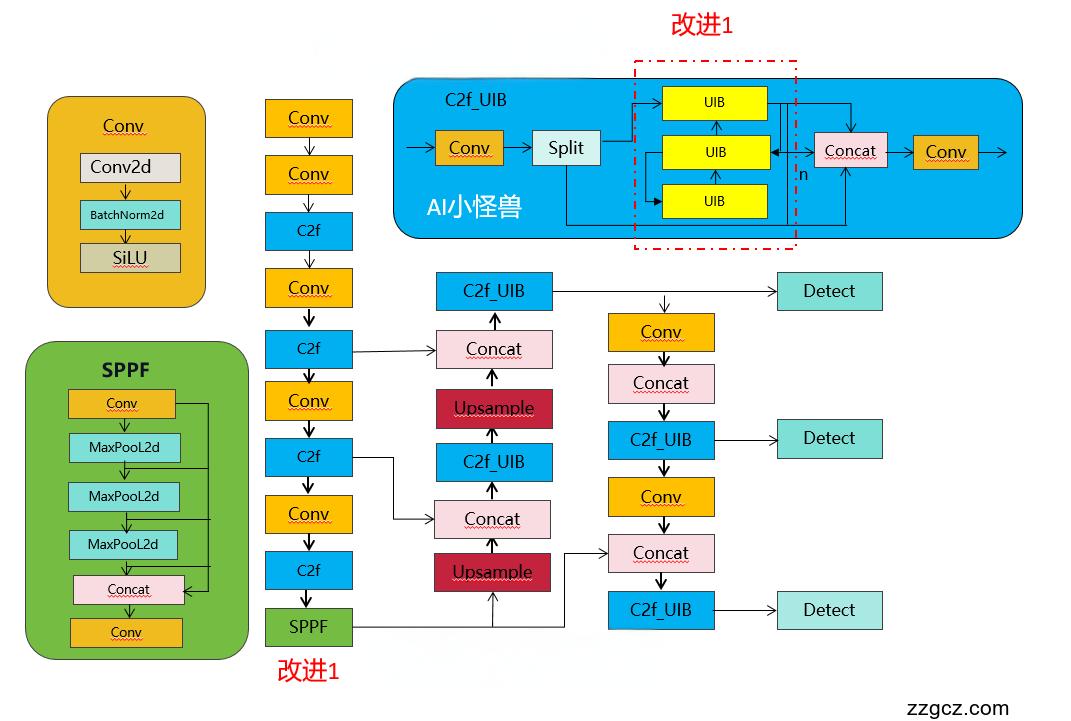
2.3 yolov8-C2f_UIB.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f_UIB, [512]] # 12
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f_UIB, [256]] # 15 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f_UIB, [512]] # 18 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f_UIBS, [1024]] # 21 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
你也可以替换backbone中的C2f