💡💡💡本文解决了什么问题:通道和空间注意之间的协同作用尚未得到充分挖掘,缺乏充分利用多语义信息的协同潜力来进行特征引导和缓解语义差异
💡💡💡本文方法:提出了一种新的空间和通道协同注意模块(SCSA),由两部分组成:可共享的多语义空间注意(SMSA)和渐进式信道自注意(PCSA)
💡💡💡新颖度足够适合paper,全网独家首发推荐指数五颗星,适用于小目标检测,高效涨点
改进1结构图:
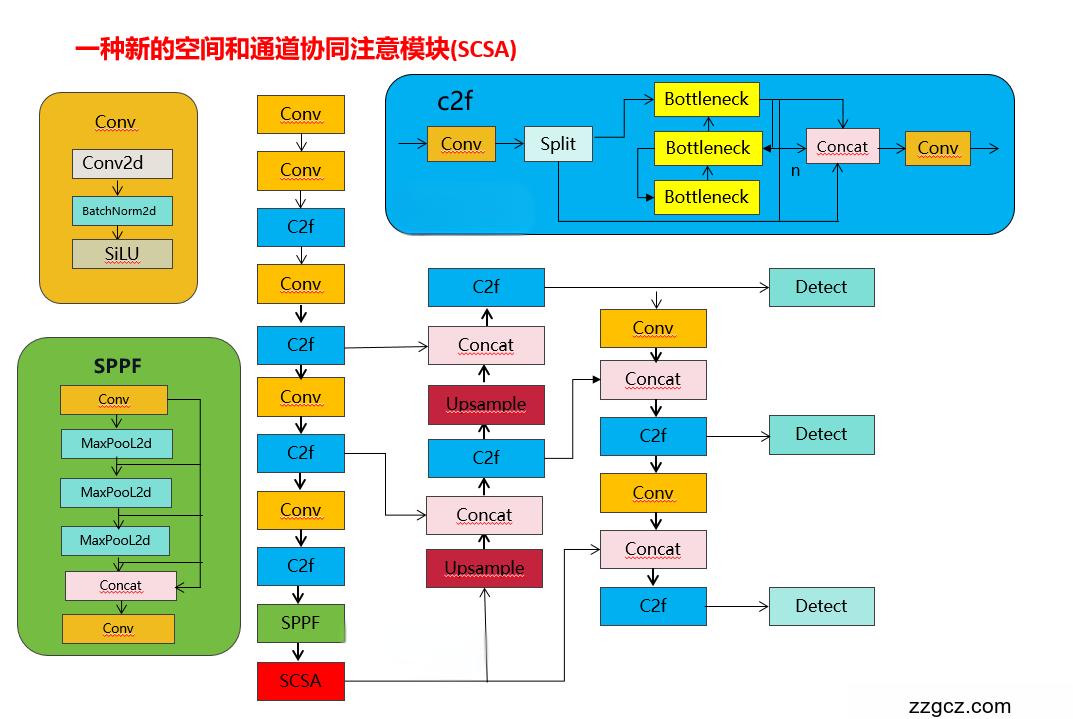
YOLOv8原创自研
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.原理介绍

论文: https://arxiv.org/pdf/2407.05128v1
摘要:通道关注和空间关注分别为提取各种下游视觉的特征依赖关系和空间结构关系带来了显著的改进任务。它们的结合更有利于发挥各自的优势,但通道和空间注意之间的协同作用尚未得到充分挖掘,缺乏充分利用多语义信息的协同潜力来进行特征引导和缓解语义差异。本研究试图在多个语义层面揭示空间和通道注意之间的协同关系,提出了一个新的空间和通道协同注意模块(SCSA)。我们的SCSA由两部分组成:可共享的多语义空间注意(SMSA)和渐进式信道自注意(PCSA)。SMSA集成多语义信息,采用渐进式压缩策略,在PCSA的信道自注意中注入判别性空间先验,有效引导信道重新校准。此外,PCSA中基于自注意机制的鲁棒特征交互进一步缓解了SMSA中不同子特征之间的多语义信息差异。我们在7个基准数据集上进行了广泛的实验,包括ImageNet-1K上的分类、MSCOCO 2017上的目标检测、ADE20K上的分割以及其他4个复杂场景检测数据集。我们的研究结果表明,我们提出的SCSA不仅超越了当前最先进的关注水平,而且在各种任务场景中表现出增强的泛化能力。

在本节中,我们首先讨论SMSA模块,该模块探讨轻量级多语义信息引导的好处。接下来,我们介绍了PCSA模块,该模块利用渐进式压缩策略和信道自关注来缓解语义差异。多语义引导和语义差异缓解的协同效应促使我们提出了多语义引导模块。整个体系结构如图2所示。
图2所示。我们提出的SCSA,它使用多语义空间信息来指导信道自注意的学习。B表示批大小,C表示通道数,H和W分别对应特征映射的高度和宽度。变量n表示子特征被分成的组数,1P表示单个像素。

2.如何加入YOLOv8
3.1新建加入ultralytics/nn/attention/SCSA.py
import typing as t
import torch
import torch.nn as nn
from einops import rearrange
from mmengine.model import BaseModule
from ultralytics.nn.modules.conv import Conv
__all__ = ['SCSA']
class SCSA(BaseModule):
def __init__(
self,
dim: int,
head_num: int,
window_size: int = 7,
group_kernel_sizes: t.List[int] = [3, 5, 7, 9],
qkv_bias: bool = False,
fuse_bn: bool = False,
norm_cfg: t.Dict = dict(type='BN'),
act_cfg: t.Dict = dict(type='ReLU'),
down_sample_mode: str = 'avg_pool',
attn_drop_ratio: float = 0.,
gate_layer: str = 'sigmoid',
):
super(SCSA, self).__init__()
self.dim = dim
self.head_num = head_num
self.head_dim = dim // head_num
self.scaler = self.head_dim ** -0.5
self.group_kernel_sizes = group_kernel_sizes
self.window_size = window_size
self.qkv_bias = qkv_bias
self.fuse_bn = fuse_bn
self.down_sample_mode = down_sample_mode
assert self.dim // 4, 'The dimension of input feature should be divisible by 4.'
self.group_chans = group_chans = self.dim // 4
self.local_dwc = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[0],
padding=group_kernel_sizes[0] // 2, groups=group_chans)
self.global_dwc_s = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[1],
padding=group_kernel_sizes[1] // 2, groups=group_chans)
self.global_dwc_m = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[2],
padding=group_kernel_sizes[2] // 2, groups=group_chans)
self.global_dwc_l = nn.Conv1d(group_chans, group_chans, kernel_size=group_kernel_sizes[3],
padding=group_kernel_sizes[3] // 2, groups=group_chans)
self.sa_gate = nn.Softmax(dim=2) if gate_layer == 'softmax' else nn.Sigmoid()
self.norm_h = nn.GroupNorm(4, dim)
self.norm_w = nn.GroupNorm(4, dim)
self.conv_d = nn.Identity()
self.norm = nn.GroupNorm(1, dim)
self.q = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)
self.k = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)
self.v = nn.Conv2d(in_channels=dim, out_channels=dim, kernel_size=1, bias=qkv_bias, groups=dim)
self.attn_drop = nn.Dropout(attn_drop_ratio)
self.ca_gate = nn.Softmax(dim=1) if gate_layer == 'softmax' else nn.Sigmoid()
if window_size == -1:
self.down_func = nn.AdaptiveAvgPool2d((1, 1))
else:
if down_sample_mode == 'recombination':
self.down_func = self.space_to_chans
# dimensionality reduction
self.conv_d = nn.Conv2d(in_channels=dim * window_size ** 2, out_channels=dim, kernel_size=1, bias=False)
elif down_sample_mode == 'avg_pool':
self.down_func = nn.AvgPool2d(kernel_size=(window_size, window_size), stride=window_size)
elif down_sample_mode == 'max_pool':
self.down_func = nn.MaxPool2d(kernel_size=(window_size, window_size), stride=window_size)
def forward(self, x: torch.Tensor) -> torch.Tensor:
"""
The dim of x is (B, C, H, W)
"""
# Spatial attention priority calculation
b, c, h_, w_ = x.size()
# (B, C, H)
x_h = x.mean(dim=3)
l_x_h, g_x_h_s, g_x_h_m, g_x_h_l = torch.split(x_h, self.group_chans, dim=1)
# (B, C, W)
x_w = x.mean(dim=2)
l_x_w, g_x_w_s, g_x_w_m, g_x_w_l = torch.split(x_w, self.group_chans, dim=1)
x_h_attn = self.sa_gate(self.norm_h(torch.cat((
self.local_dwc(l_x_h),
self.global_dwc_s(g_x_h_s),
self.global_dwc_m(g_x_h_m),
self.global_dwc_l(g_x_h_l),
), dim=1)))
x_h_attn = x_h_attn.view(b, c, h_, 1)
x_w_attn = self.sa_gate(self.norm_w(torch.cat((
self.local_dwc(l_x_w),
self.global_dwc_s(g_x_w_s),
self.global_dwc_m(g_x_w_m),
self.global_dwc_l(g_x_w_l)
), dim=1)))
x_w_attn = x_w_attn.view(b, c, 1, w_)
x = x * x_h_attn * x_w_attn
# Channel attention based on self attention
# reduce calculations
y = self.down_func(x)
y = self.conv_d(y)
_, _, h_, w_ = y.size()
# normalization first, then reshape -> (B, H, W, C) -> (B, C, H * W) and generate q, k and v
y = self.norm(y)
q = self.q(y)
k = self.k(y)
v = self.v(y)
# (B, C, H, W) -> (B, head_num, head_dim, N)
q = rearrange(q, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),
head_dim=int(self.head_dim))
k = rearrange(k, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),
head_dim=int(self.head_dim))
v = rearrange(v, 'b (head_num head_dim) h w -> b head_num head_dim (h w)', head_num=int(self.head_num),
head_dim=int(self.head_dim))
# (B, head_num, head_dim, head_dim)
attn = q @ k.transpose(-2, -1) * self.scaler
attn = self.attn_drop(attn.softmax(dim=-1))
# (B, head_num, head_dim, N)
attn = attn @ v
# (B, C, H_, W_)
attn = rearrange(attn, 'b head_num head_dim (h w) -> b (head_num head_dim) h w', h=int(h_), w=int(w_))
# (B, C, 1, 1)
attn = attn.mean((2, 3), keepdim=True)
attn = self.ca_gate(attn)
return attn * x
3.2 注册ultralytics/nn/tasks.py
1)SCSA进行注册
from ultralytics.nn.attention.SCSA import SCSA2)第二处修改
2)修改def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)
不要直接复制以下代码,只需要将 SCSA加入你的工程
n = n_ = max(round(n * depth), 1) if n > 1 else n # depth gain
if m in (
Classify,
Conv,
ConvTranspose,
GhostConv,
Bottleneck,
GhostBottleneck,
SPP,
SPPF,
DWConv,
Focus,
BottleneckCSP,
C1,
C2,
C2f,
C2fAttn,
C3,
C3TR,
C3Ghost,
nn.ConvTranspose2d,
DWConvTranspose2d,
C3x,
RepC3,
SCSA
):
c1, c2 = ch[f], args[0]
if c2 != nc: # if c2 not equal to number of classes (i.e. for Classify() output)
c2 = make_divisible(min(c2, max_channels) * width, 8)
args = [c1, c2, *args[1:]]
if m in (BottleneckCSP, C1, C2, C2f, C2fAttn, C3, C3TR, C3Ghost, C3x, RepC3):
args.insert(2, n) # number of repeats
n = 12.3 yolov8-SCSA.yaml
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLOv8 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect
# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolov8n.yaml' will call yolov8.yaml with scale 'n'
# [depth, width, max_channels]
n: [0.33, 0.25, 1024] # YOLOv8n summary: 225 layers, 3157200 parameters, 3157184 gradients, 8.9 GFLOPs
s: [0.33, 0.50, 1024] # YOLOv8s summary: 225 layers, 11166560 parameters, 11166544 gradients, 28.8 GFLOPs
m: [0.67, 0.75, 768] # YOLOv8m summary: 295 layers, 25902640 parameters, 25902624 gradients, 79.3 GFLOPs
l: [1.00, 1.00, 512] # YOLOv8l summary: 365 layers, 43691520 parameters, 43691504 gradients, 165.7 GFLOPs
x: [1.00, 1.25, 512] # YOLOv8x summary: 365 layers, 68229648 parameters, 68229632 gradients, 258.5 GFLOPs
# YOLOv8.0n backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
- [-1, 1, SCSA, [1024]] # 10
# YOLOv8.0n head
head:
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, "nearest"]]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 16 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 13], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 19 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 10], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 22 (P5/32-large)
- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)