098Transformers 库解决了哪些问题
🤗 Transformers 库解决了哪些问题¶
在🤗 Transformers 的应用场景一文中,您了解了自然语言处理(NLP)、语音和音频、计算机视觉任务以及它们的一些重要应用。本页面将详细解释这些任务的解决方案,并解释模型内部的工作原理。虽然每种任务的解决方案可能各不相同,但 Transformer 模型的基本思路是相似的。由于其灵活的架构,大多数模型是编码器、解码器或编码器-解码器结构的变体。此外,我们的库中还包含几种卷积神经网络(CNN),这些网络仍然用于计算机视觉任务。我们也将解释现代 CNN 的工作原理。
要解释任务的解决方法,我们将详细说明模型内部的工作流程,以便输出有用的预测结果。
- Wav2Vec2 用于音频分类和自动语音识别(ASR)
- ViT(Vision Transformer) 和 ConvNeXT 用于图像分类
- DETR 用于目标检测
- Mask2Former 用于图像分割
- GLPN 用于深度估计
- BERT 用于使用编码器的任务,如文本分类、标记分类和问答
- GPT2 用于使用解码器的任务,如文本生成
- BART 用于使用编码器-解码器的任务,如摘要和翻译
在继续阅读之前,了解原始 Transformer 架构的一些基本知识是有益的。了解编码器、解码器和注意力机制的工作原理,有助于您理解不同 Transformer 模型的工作原理。如果您是初学者或需要复习,请查看我们的课程以获取更多信息!
语音和音频¶
Wav2Vec2 是一种自监督模型,预训练于无标签语音数据,并在有标签数据上进行微调,用于音频分类和自动语音识别(ASR)。
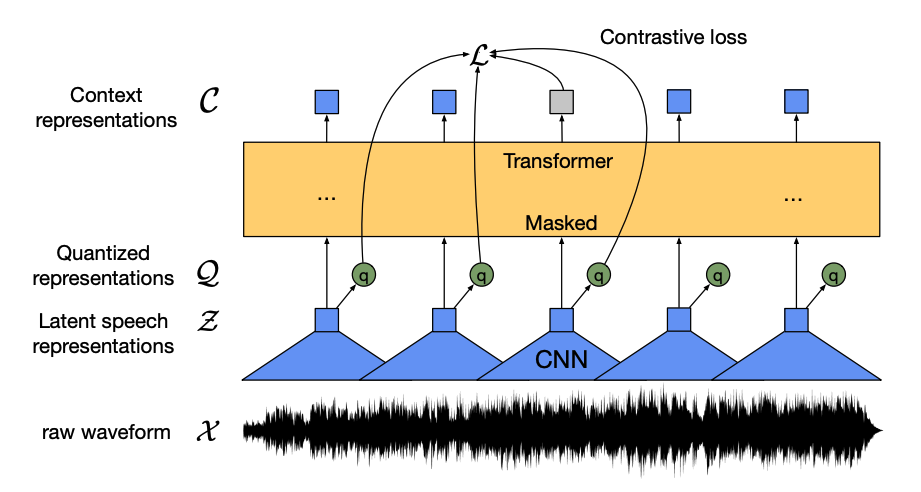
该模型有四个主要组件:
- 特征编码器:它接收原始音频波形,将其归一化为零均值和单位方差,并将其转换为一系列长度为 20ms 的特征向量。
- 由于波形是连续的,无法像文本那样分割成离散单元,因此特征向量被传递给量化模块,该模块试图学习离散的语音单元。语音单元从一组代码字中选择,称为词汇表。从词汇表中选择最能代表连续音频输入的向量或语音单元,并将其传递给模型。
- 约一半的特征向量被随机遮掩,并将遮掩的特征向量传递给上下文网络,这是一个 Transformer 编码器,它还添加了相对位置嵌入。
- 上下文网络的预训练目标是一个对比任务。模型须从一组错误的选项中预测遮掩部分的真实量化语音表示,这鼓励模型找到最相似的上下文向量和量化语音单元(目标标签)。
预训练后,您可以微调 Wav2Vec2 以用于音频分类或自动语音识别!
音频分类¶
要使用预训练模型进行音频分类,请在基础 Wav2Vec2 模型上添加一个序列分类头。分类头是线性层,它接收编码器的隐藏状态。隐藏状态表示每个音频帧中学习到的特征,这些特征长度不同。为了创建一个固定长度的向量,隐藏状态首先进行池化,然后转换为类标签的逻辑值。计算逻辑值和目标之间的交叉熵损失,以找到最有可能的类别。
想尝试音频分类吗?请查看我们的音频分类指南,学习如何微调 Wav2Vec2 并用于推理!
自动语音识别¶
要使用预训练模型进行自动语音识别,请在基础 Wav2Vec2 模型上添加一个语言模型头,用于连接时序分类(CTC)。语言模型头是线性层,它接收编码器的隐藏状态并将其转换为逻辑值。每个逻辑值代表一个标记类(标记数量来自任务词汇表)。计算 CTC 损失以找到最有可能的标记序列,然后对其进行解码,以生成转录文本。
想尝试自动语音识别吗?请查看我们的自动语音识别指南,学习如何微调 Wav2Vec2 并用于推理!
计算机视觉¶
处理计算机视觉任务有两种方法:
- 将图像分割成一系列补丁,并使用 Transformer 并行处理它们。
- 使用现代 CNN(如 ConvNeXT),其依赖于卷积层,但采用了现代网络设计。
第三种方法是将 Transformer 与卷积混合使用(例如 Convolutional Vision Transformer 或 LeViT)。我们不讨论这些方法,因为它们只是结合了前面两种方法。
ViT 和 ConvNeXT 常用于图像分类,而对于目标检测、分割和深度估计等其他视觉任务,我们将分别查看 DETR、Mask2Former 和 GLPN,这些模型更适合这些任务。
图像分类¶
ViT 和 ConvNeXT 都可用于图像分类,主要区别在于:ViT 使用注意力机制,而 ConvNeXT 使用卷积。
Transformer¶
ViT 完全用纯 Transformer 架构替代了卷积。如果您熟悉原始 Transformer,那么您已经掌握了理解 ViT 的大部分内容。

ViT 引入的主要变化是图像如何输入到 Transformer:
- 将图像分割为非重叠的方形补丁,每个补丁转换为向量或补丁嵌入。补丁嵌入由卷积 2D 层生成,以创建适当的输入维度(对于基础 Transformer 每个补丁嵌入的维度是 768)。例如,如果图像大小为 224x224 像素,可以将其分割为 196 个 16x16 的图像补丁。就像文本被分词为单词一样,图像也被“分词”为一系列补丁。
- 添加一个可学习嵌入——特殊
[CLS]标记——到补丁嵌入的开头,就像 BERT 一样。最终的[CLS]标记的隐藏状态用作分类头的输入;其他输出被忽略。这个标记帮助模型学习如何编码图像表示。 - 将位置嵌入添加到补丁和可学习嵌入中,因为模型不知道图像补丁的顺序。位置嵌入也是可学习的,并且与补丁嵌入具有相同的大小。最后,所有嵌入被传递给 Transformer 编码器。
- 输出,特别是带有
[CLS]标记的输出,被传递给多层感知器头(MLP)。ViT 的预训练目标是简单的分类。像其他分类头一样,MLP 头将输出转换为类标签的逻辑值,并计算交叉熵损失以找到最有可能的类别。
想尝试图像分类吗?请查看我们的图像分类指南,学习如何微调 ViT 并用于推理!
卷积神经网络(CNN)¶
本节简要解释卷积,但了解它们如何改变图像的形状和大小是有帮助的。如果您不熟悉卷积,请查看 fastai 书籍中的卷积神经网络章节!
ConvNeXT 是一种卷积神经网络架构,采用了新的现代网络设计以提高性能。然而,卷积仍然是模型的核心。从高层次看,卷积是将一个小矩阵(内核)与图像像素的小窗口相乘的操作。它从该窗口中计算一些特征,例如特定纹理或线条的曲率。然后它滑动到下一个像素窗口;卷积的距离称为步幅。

基本卷积(不使用填充或步幅),取自深度学习卷积算术指南
您可以将此输出传递给另一个卷积层,随着每层的增加,网络学习到更复杂和抽象的东西,如热狗或火箭。卷积层之间通常添加一个池化层,以减少维度并使模型对特征位置的变化更具鲁棒性。

ConvNeXT 通过五种方式现代化 CNN:
- 改变每个阶段的块数,并“打补丁”图像,使用更大的步幅和对应的内核大小。非重叠滑动窗口使这种打补丁策略类似于 ViT 如何将图像分割为补丁。
- 瓶颈层缩小通道数量并恢复,因为 1x1 卷积更快,您可以增加深度。倒瓶颈层则相反,它通过扩展通道数量并缩小来提高内存效率。
- 用深度卷积代替瓶颈层中的典型 3x3 卷积层,深度卷积对每个输入通道分别应用卷积,然后将它们重新堆叠在一起。这拓宽了网络宽度,提高了性能。
- ViT 具有全局感受野,这意味着它可以一次性看到更多内容,这要归功于其注意力机制。ConvNeXT 通过将内核大小增加到 7x7 来模仿这种效果。
- ConvNeXT 还在几个层设计上模仿 Transformer 模型。减少了激活和归一化层的数量,激活函数从 ReLU 切换为 GELU,并使用 LayerNorm 代替 BatchNorm。
卷积块的输出被传递给分类头,将输出转换为逻辑值,并计算交叉熵损失以找到最有可能的标签。
目标检测¶
DETR(DEtection TRansformer)是一种端到端的目标检测模型,结合了 CNN 和 Transformer 编码器-解码器。
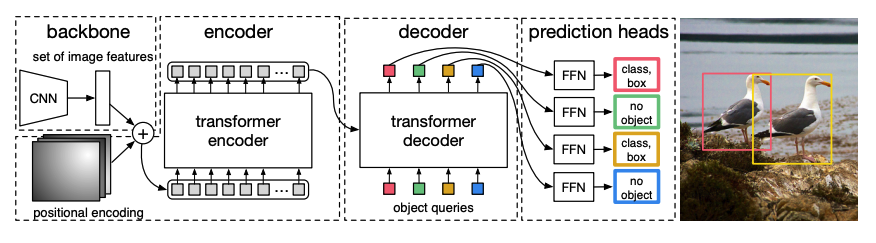
- 预训练的 CNN 骨干接受图像(由像素值表示),并创建低分辨率的特征图。对特征图应用 1x1 卷积以降低维度,生成具有高级图像表示的新特征图。由于 Transformer 是序列模型,特征图被展平为特征向量的序列,并与位置嵌入结合。
- 特征向量被传递给编码器,编码器使用其注意力层学习图像表示。然后编码器的隐藏状态与对象查询结合在解码器中。对象查询是可学习的嵌入,专注于图像的不同区域,并在通过每个注意力层时进行更新。解码器的隐藏状态被传递给前馈网络,以预测每个对象查询的边界框坐标和类别标签,或预测为“无对象”。
DETR 并行解码每个对象查询,输出 N 个最终预测,其中 N 是查询的数量。与通常一次预测一个元素的自回归模型不同,目标检测是集预测任务(
边界框,类别标签),在单次传递中输出 N 个预测。 - DETR 在训练期间使用二分匹配损失,将其固定数量的预测与固定数量的真实标签进行比较。如果 N 个标签中真实标签较少,则用“无对象”类别填充。此损失函数鼓励 DETR 找到预测与真实标签之间的一对一对应关系。如果边界框或类别标签不正确,会计算损失。同样,如果 DETR 预测了一个不存在的对象,它也会受到惩罚,这促使 DETR 寻找图像中的其他对象,而不是只关注一个突出对象。
目标检测头添加在 DETR 顶部,以找到类别标签和边界框的坐标。检测头有两个组件:一个线性层,将解码器的隐藏状态转换为类别标签的逻辑值;以及一个多层感知器,用于预测边界框。
想尝试目标检测吗?请查看我们的目标检测指南,学习如何微调 DETR 并用于推理!
图像分割¶
Mask2Former 是一种通用架构,用于解决各种图像分割任务。传统分割模型通常针对特定的图像分割子任务,如实例、语义或全景分割。Mask2Former 将每个任务视为掩码分类问题。掩码分类将像素分组为 N 个片段,并为给定图像预测 N 个掩码及其对应的类别标签。让我们解释 Mask2Former 的工作原理,然后您可以尝试微调 SegFormer。

Mask2Former 有三个主要组件:
- Swin 骨干接受图像,并通过三个连续的 3x3 卷积创建低分辨率图像特征图。
- 特征图被传递给像素解码器,像素解码器逐步上采样低分辨率特征,生成高分辨率的像素嵌入。像素解码器实际上生成多尺度特征(包含低分辨率和高分辨率特征),分辨率为原始图像的 1/32、1/16 和 1/8。
- 这些不同尺度的特征图依次传递给一个 Transformer 解码器层,以捕捉高分辨率特征中的小对象。Mask2Former 的关键是解码器中的掩码注意力机制。与可以关注整个图像的交叉注意力不同,掩码注意力仅关注图像的特定区域。这使得速度更快,并且由于局部特征就足够模型学习,因此性能更好。
- 像DETR一样,Mask2Former 也使用可学习的对象查询,并将它们与像素解码器的图像特征结合,进行集预测(
类别标签,掩码预测)。解码器的隐藏状态被传递给线性层,转换为类别标签的逻辑值。计算逻辑值与类别标签之间的交叉熵损失,以找到最有可能的类别标签。
掩码预测是通过将像素嵌入与最终解码器的隐藏状态结合生成的。计算逻辑值与真实掩码之间的 sigmoid 交叉熵和骰子损失,以找到最有可能的掩码。
想尝试图像分割吗?请查看我们的图像分割指南,学习如何微调 SegFormer 并用于推理!
深度估计¶
GLPN(Global-Local Path Network)是用于深度估计的 Transformer,结合了 SegFormer 编码器和轻量解码器。

- 类似 ViT,图像被分割成一系列补丁,但这些图像补丁更小,更适合密集预测任务(如分割或深度估计)。图像补丁被转换为补丁嵌入(有关补丁嵌入的详细信息,请参阅图像分类部分),并传递给编码器。
- 编码器接受补丁嵌入,并通过多个编码器块输出最终的隐藏状态。每个块包含注意力层和 Mix-FFN 层。后者用于提供位置信息。每个编码器块的末尾是一个补丁合并层,用于创建分层表示。每个邻近补丁的特征被连接,然后通过线性层应用于连接的特征,以减少补丁数量,降低到 1/4 的分辨率。这成为下一个编码器块的输入,整个过程重复进行,直到生成分辨率为 1/8、1/16 和 1/32 的图像特征。
- 轻量解码器接受编码器的最后一个特征图(1/32 分辨率),并上采样到 1/16 分辨率。从这里开始,特征被传递给选择性特征融合(SFF)模块,该模块为每个特征选择和组合局部和全局特征,并将其上采样到 1/8 分辨率。此过程重复进行,直到解码特征与原始图像大小相同。输出通过两个卷积层,然后应用 sigmoid 激活函数以预测每个像素的深度。
自然语言处理¶
Transformer 最初是为机器翻译设计的,自那时以来,它几乎已成为解决所有 NLP 任务的默认架构。一些任务更适合使用 Transformer 的编码器结构,而其他任务更适合使用解码器。还有一些任务则结合使用编码器-解码器结构。
文本分类¶
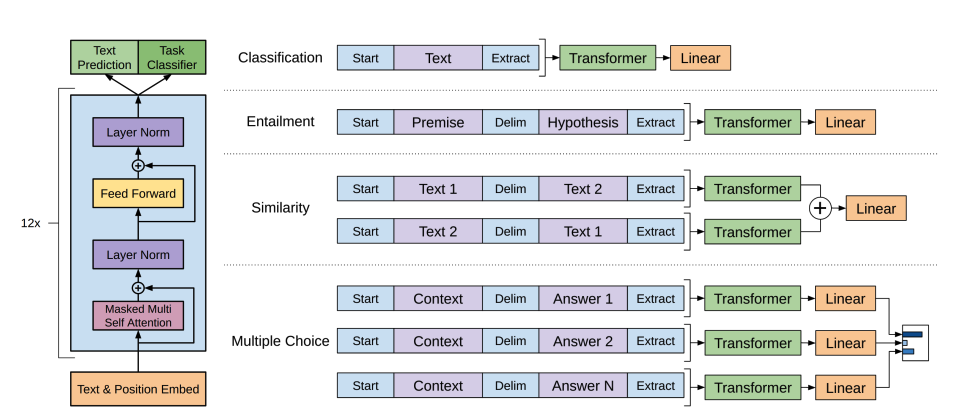
BERT 是一种仅编码器模型,首次有效地实现了双向性,以学习更丰富的文本表示。
- BERT 使用 WordPiece 分词生成文本的标记嵌入。为了区分单个句子和句子对,添加了特殊
[SEP]标记。每个文本序列的开头添加一个特殊[CLS]标记。最终的[CLS]标记输出用于分类任务的分类头输入。BERT 还添加了段嵌入,以表示标记是属于第一个句子还是第二个句子。 - BERT 的预训练有两个目标:掩码语言建模和下一句预测。在掩码语言建模中,一定比例的输入标记被随机遮掩,模型需要预测这些。这解决了双向性的问题,模型无法通过看到所有单词来“预测”下一个单词。预测的遮掩标记的最终隐藏状态被传递给具有 softmax 的前馈网络,以预测遮掩的单词。
第二个预训练目标是下一句预测。模型必须预测句子 B 是否跟在句子 A 之后。一半的时间句子 B 是下一个句子,另一半时间句子 B 是随机句子。预测结果(是否为下一句)被传递给具有 softmax 的前馈网络,以预测两个类别(
IsNext和NotNext)。 - 输入嵌入被传递给多个编码器层,以输出最终的隐藏状态。
要使用预训练模型进行文本分类,请在基础 BERT 模型上添加一个序列分类头。序列分类头是一个线性层,它接收最终的隐藏状态并执行线性变换以转换为逻辑值。计算逻辑值与目标之间的交叉熵损失,以找到最有可能的标签。
想尝试文本分类吗?请查看我们的文本分类指南,学习如何微调 DistilBERT 并用于推理!
标记分类¶
要使用 BERT 进行标记分类任务(如命名实体识别 NER),请在基础 BERT 模型上添加一个标记分类头。标记分类头是一个线性层,它接收最终的隐藏状态并执行线性变换以转换为逻辑值。计算逻辑值与每个标记之间的交叉熵损失,以找到最有可能的标签。
想尝试标记分类吗?请查看我们的标记分类指南,学习如何微调 DistilBERT 并用于推理!
问答¶
要使用 BERT 进行问答任务,请在基础 BERT 模型上添加一个跨度分类头。这个线性层接收最终的隐藏状态并执行线性变换,以计算答案的跨度起始和结束逻辑值。计算逻辑值与标签位置之间的交叉熵损失,以找到最有可能对应答案的文本跨度。
想尝试问答吗?请查看我们的问答指南,学习如何微调 DistilBERT 并用于推理!
💡 一旦 BERT 进行预训练,使用它进行不同任务是多么容易!您只需要在预训练模型上添加一个特定的头部,以操作隐藏状态,生成所需的输出!
文本生成¶
GPT-2 是一种仅解码器模型,预训练于大量文本。给定提示,它可以生成令人信服的文本(尽管不总是真实的!),并完成其他 NLP 任务,如问答,尽管它并不是为此专门训练的。
- GPT-2 使用 字节对编码(BPE) 对词进行分词并生成标记嵌入。位置编码被添加到标记嵌入中,以指示序列中每个标记的位置。输入嵌入被传递给多个解码器块,以输出最终的隐藏状态。在每个解码器块内,GPT-2 使用掩码自注意力层,这意味着 GPT-2 不能关注未来的标记。它只能关注左侧的标记。这与 BERT 的
mask标记不同,因为在掩码自注意力中,使用注意力掩码将未来标记的分数设置为0。 - 来自解码器的输出被传递给语言模型头,执行线性变换以将隐藏状态转换为逻辑值。标签是序列中的下一个标记,创建方式是将逻辑值向右移动一位。计算移位后的逻辑值与标签之间的交叉熵损失,以输出下一个最有可能的标记。
GPT-2 的预训练目标完全基于因果语言建模,即预测序列中的下一个词。这使得 GPT-2 特别适合涉及生成文本的任务。
想尝试文本生成吗?请查看我们的因果语言建模指南,学习如何微调 DistilGPT-2 并用于推理!
有关文本生成的更多信息,请查看文本生成策略指南!
摘要¶
编码器-解码器模型(如 BART 和 T5)专为摘要任务的序列到序列模式设计。我们将在本节中解释 BART 的工作原理,然后您可以尝试微调 T5。
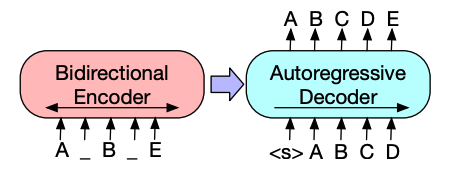
- BART 的编码器架构与 BERT 非常相似,接受文本的标记嵌入和位置嵌入。BART 通过破坏输入并用解码器重建它来进行预训练。与其他具有特定破坏策略的编码器不同,BART 可以应用任何类型的破坏。文本填充破坏策略效果最好。在文本填充中,一定数量的文本片段被替换为单个
mask标记。这很重要,因为模型必须预测被遮掩的标记,它教导模型预测缺失的标记数量。输入嵌入和被遮掩的片段被传递给编码器,输出最终的隐藏状态,但与 BERT 不同,BART 并未在末尾添加一个最终的前馈网络来预测词。 - 编码器的输出被传递给解码器,解码器必须从编码器的输出中预测被遮掩的标记和未被破坏的标记。这为解码器提供了额外的上下文,以帮助其恢复原始文本。解码器的输出被传递给语言模型头,执行线性变换以将隐藏状态转换为逻辑值。计算逻辑值与标签之间的交叉熵损失,标签只是向右移动一位的标记。
想尝试摘要吗?请查看我们的摘要指南,学习如何微调 T5 并用于推理!
有关文本生成的更多信息,请查看文本生成策略指南!
翻译¶
翻译是另一个序列到序列任务的示例,这意味着您可以使用编码器-解码器模型(如 BART 或 T5)来实现它。我们将在本节中解释 BART 的工作原理,然后您可以尝试微调 T5。
BART 通过添加一个独立的随机初始化编码器来适应翻译任务。该编码器将源语言映射为输入,可以被解码器解码为目标语言。这个新编码器的嵌入被传递给预训练的编码器,而不是原始的词嵌入。源编码器通过更新源编码器、位置嵌入和输入嵌入,使用模型输出的交叉熵损失进行训练。在第一步中,模型参数被冻结,所有模型参数在第二步中一起训练。
BART 随后推出了多语言版本 mBART,旨在进行翻译,并在许多不同语言上进行了预训练。
想尝试翻译吗?请查看我们的翻译指南,学习如何微调 T5 并用于推理!
有关文本生成的更多信息,请查看文本生成策略指南!